上一篇《Python 网络爬虫实战:爬取人民日报新闻文章》发布之后,确实帮到了不少朋友。
前几天,我好哥们问我:我想爬另一个日报新闻网站,网页结构几乎跟人民日报几乎一模一样,但是我用你的那个代码去爬却爬不下来数据呢?
顺着哥儿们发来的网址(网站传送地址:解放日报),我点进去看了一下,界面大概长这样。
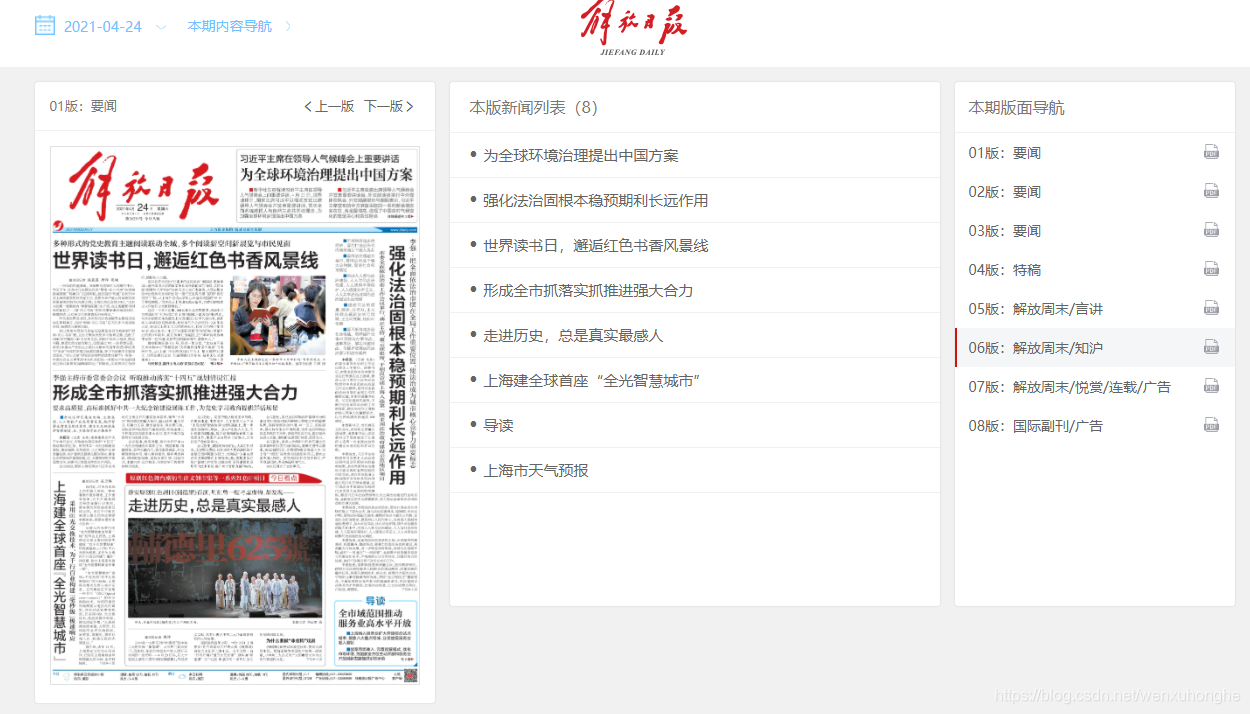
跟人民日报的主页界面非常相似,都是 版面列表 -- 文章列表 -- 文章详情 的这种结构。

本来我觉得肯定是我这哥儿们代码基础不过关,报的语法错误,先 “嘲讽” 他一波,然后帮他改好就得了。
没想到一分析,才发现这个网站的新闻数据,是 Ajax 动态加载出来的(具体区别就是,人民日报的数据是提前生成好在网页里,跟网页一起返回显示的;而解放日报则是分开的,先返回一个空网页,然后再通过数据的接口请求数据,把数据动态加载到空网页里显示)
虽然这个动态加载的爬虫也并不难,花了十来分钟就改完了,但是我感觉这还是蛮典型的一种类型的,所以趁这个机会拿来跟大家分享一下,遇到了这种类似的情况应该怎么做。
一、分析网站
其实第一步应该是 明确需求 的,就是要明确我们需要什么样的数据,希望以什么样的形式才保存等等。不过由于我们这个跟《人民日报》爬虫目标一致,所以需求部分就暂且略过了。
我们直接来分析网站。
1.1 数据动态加载是怎么回事儿
很多刚接触爬虫的同学,上来 F12 打开开发者工具,就咔咔定位数据找标签,如果是像人民日报那样的静态网页还好,你分析时看到的标签是什么样子,用代码爬的时候基本上也是那个样子;但是遇到解放日报这种动态加载的网站,就直接懵逼了,明明我标签位置,名字,class 和 id 什么的都没写错,为什么爬取的时候就总是报错说找不到标签呢?
答案就是,你找的那个标签是动态生成的,原始网页源码里根本没有,当然找不到了。
大家看下面,这是解放日报的版面导航列表。
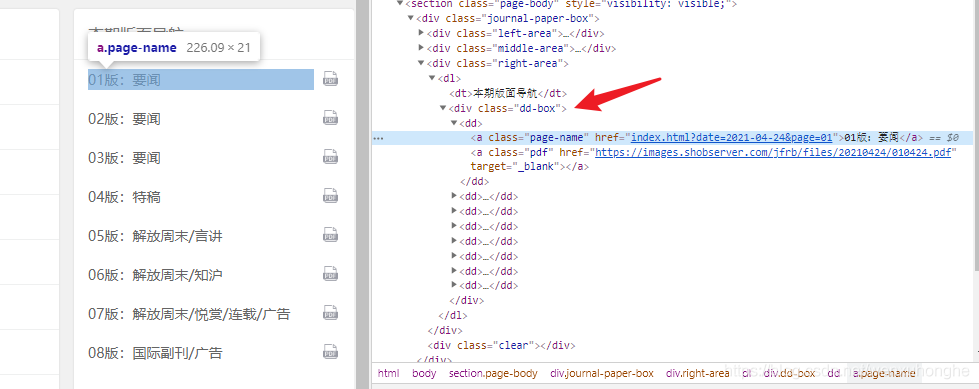
一般大家爬取的时候,会先找到这个 <div class="dd-box"> 标签,然后在这个标签下找到所有的 <dd> 标签,然后再找 <a> 标签,然后就找到了想要的数据。
然鹅,当我们打开查看网页源码的时候(chrome 浏览器为例,鼠标右键,查看网页源代码),发现源代码里并没有我们需要的数据,而是一个类似于模板的东西。数据是通过后续动态的加载进来的。
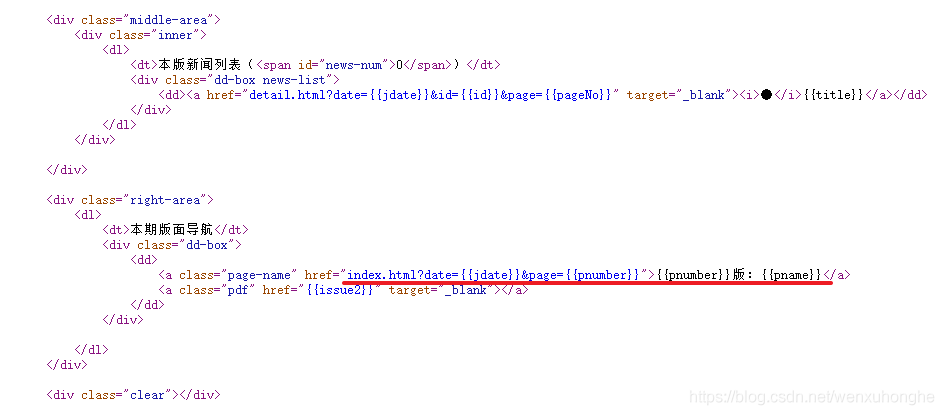
当我们用爬虫去爬的时候,获取到的也是这样的源代码,当然取不到数据啦。
Tips1: 分析网页的时候,可以先查看一下网页源代码,看看自己需要的数据是否在里面,如果有,则可以继续接着分析,如果没有,说明数据是动态加载进来的,要换个思路。
1.2 数据是怎么获取到的
既然网页源代码中找不到数据,那么我们去哪儿获得数据呢?
这就涉及到一个词,叫 “抓包” ,可能听上去很高深很难的样子,其实很简单的。我们知道数据肯定是通过发起 网络请求 获得的,就是网页向服务器发送一条请求,然后服务器把需要的数据回复回来,我们把网页向服务器发送的请求,和浏览器返回的数据,使用一些工具和手段截获下来进行分析,这个过程就是 “抓包”。
可能大家听着还是有点迷糊,下面我来具体演示一下。
打开开发者工具,切换到 Network,然后刷新网页(这里可以抓到网页加载过程中,向服务器发起的各种类型的请求)。
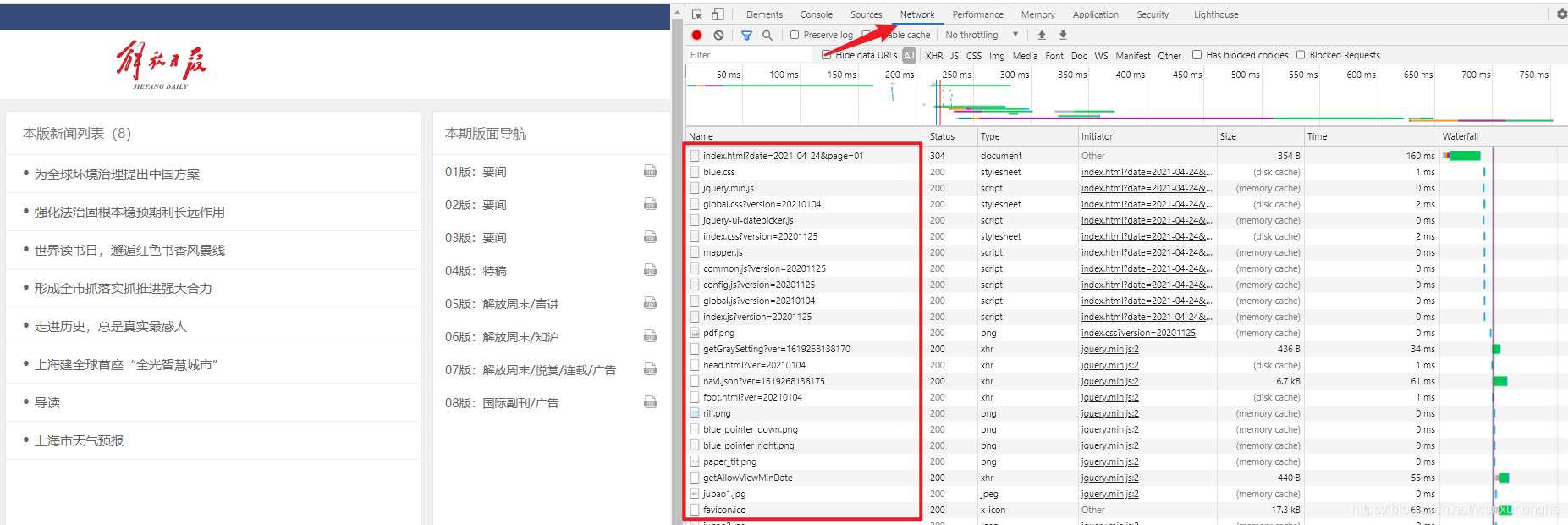
然后上图红框中圈出来的,就是我们抓取到的一条一条的请求包,有 js 脚本的,有 css 文件的,还有图片的等等各种类型的。我们要在这么多的 “请求包” 里找到包含我们需要的数据的包。
把列表里的这些请求从上到下一条一条的点开(在 Preview 里可以预览请求返回的数据),查看哪条请求是我们想要找的。
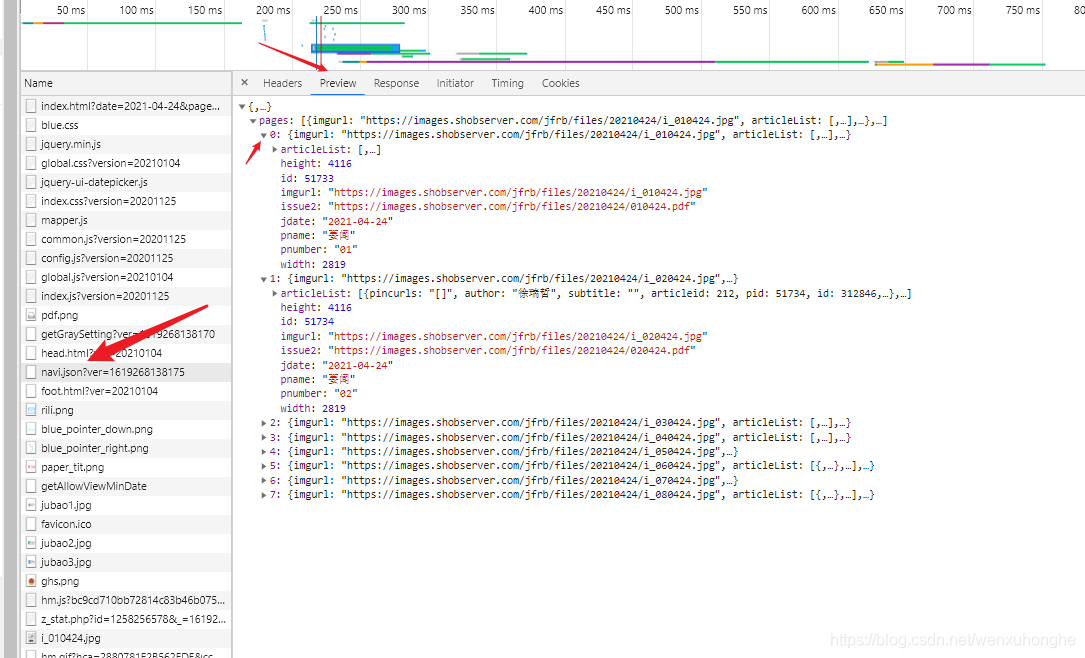
如上图箭头标识的请求点开以后,预览里的内容正好就是版面导航栏里的内容(预览里点击小箭头可以展开),我们成功找到了正确的请求。
也就是抓包成功!
1.3 抓到的包怎么用?
包含数据的请求包我们是抓到了,但是我们具体要怎么用呢?怎么把它用到爬虫程序里,通过它来爬数据呢?
还是那条请求,我们切换到 Headers 页签,可以查看到关于这条请求的一些基本信息。
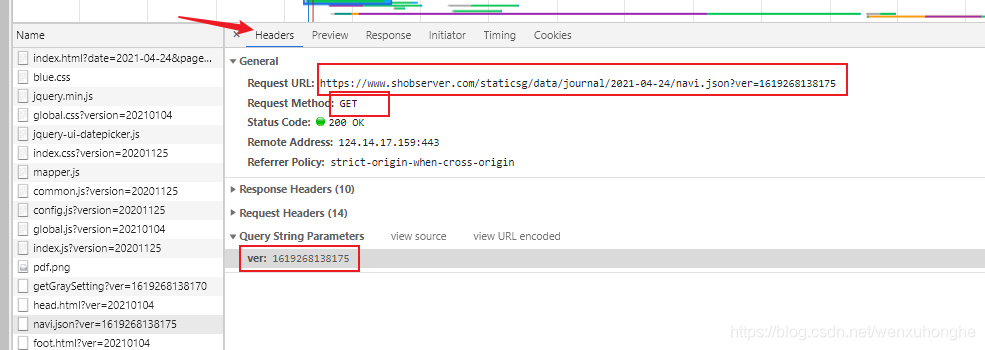
主要关注几个部分 Request URL(请求链接),Request Method(请求方法),Query String Parameters(请求参数),(当然请求头的那些东西,User-Agent ,Cookie 什么的,按照实际情况该怎么加就怎么加)。
我们的目的就是,通过 python 代码模拟浏览器发出这条请求,直接获取服务器返回的数据(返回的数据就是前面预览里的那些)。
import requests
url = "https://www.shobserver.com/staticsg/data/journal/2021-04-24/navi.json?ver=1619268138175"
r = requests.get(url)
print(r.text)我们简单写几行代码模拟一下这个过程(url 就是上图中 Request URL 的内容,requests.get() 是因为 Request Method 是 GET)。
运行结果如下,可以成功获得数据。

1.4 怎么爬其他日期的数据
运行上面的代码,我们可以获得到 2021 年 4 月 24日的新闻数据,那我们如果想爬其他日期的新闻数据该怎么办呢?
这里我们观察一下请求的 url
https://www.shobserver.com/staticsg/data/journal/2021-04-24/navi.json?ver=1619268138175
其中有一段 2021-04-24 的字样,我们猜测,这个可能就是用来控制获取数据的日期的,改成别的日期 比如 2021-04-20 再试一下。
https://www.shobserver.com/staticsg/data/journal/2021-04-20/navi.json?ver=1619268138175
发现同样可以成功。
这样我们就知道,可以通过修改 url 里的日期字符串,来爬取指定日期的数据。
1.5 解析数据
该请求返回的数据,是 json 格式的字符串,我们需要用 json 库来进行解析。
(有同学可能想问了,那么一大串乱码似的文字,你怎么知道它是 json 格式的呢?简单来讲,看两个特点,一个是大括号 {} 包起来的,另一个是键值对格式,就是 xxx : xxx 这种形式的。实在不知道怎么判断的话,就去前面讲抓包的部分,看预览的地方,如果有小箭头能够折叠展开的,就是 json 格式)

我们可以看到 pages 里有版面的列表,每个版面的 articleList 里有文章列表,包含了我们需要的版面和文章列表信息。具体解析的 Python 代码这里就不讲了,文末会贴源码。
1.6 怎么爬文章详细内容
首先点开一个文章的正文页,用前面同样的分析方法过一遍,很容易知道,正文内容也是动态加载进来的,而且正文的数据是通过下面这条请求来获得到的。

我们简单写段代码来验证一下
import requests
url = "https://www.shobserver.com/staticsg/data/journal/2021-04-24/01/article/312840.json?ver=1619271661571"
r = requests.get(url)
print(r.text)运行结果

经过对这条请求的 url 的分析,我们可以知道,/2021-04-24 是日期,/01 是指版面的编号,/312840 是文章的id。
https://www.shobserver.com/staticsg/data/journal/2021-04-24/01/article/312840.json?ver=1619271661571
至此,我们完成了对网站的分析,讲解了如何判断网站数据是动态加载还是静态加载,如果是动态加载的话如何抓包,抓包以后如何使用等等,并抓到了 新闻版面列表,文章列表,文章正文内容的请求接口。如果有哪里没有讲清楚,或者对以上内容有不太明白的地方,可以留言问我。
下面进行写代码,正式爬取。
二、编码环节
下面是爬虫源码,供大家学习交流使用,请勿用于非法用途。
import requests
import bs4
import os
import datetime
import time
import json
def fetchUrl(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
def saveFile(content, path, filename):
'''
功能:将文章内容 content 保存到本地文件中
参数:要保存的内容,路径,文件名
'''
# 如果没有该文件夹,则自动生成
if not os.path.exists(path):
os.makedirs(path)
# 保存文件
with open(path + filename, 'w', encoding='utf-8') as f:
f.write(content)
def download_jfrb(year, month, day, destdir):
'''
功能:网站 某年 某月 某日 的新闻内容,并保存在 指定目录下
参数:年,月,日,文件保存的根目录
'''
url = 'https://www.shobserver.com/staticsg/data/journal/' + year + '-' + month + '-' + day + '/navi.json'
html = fetchUrl(url)
jsonObj = json.loads(html)
for page in jsonObj["pages"]:
pageName = page["pname"]
pageNo = page["pnumber"]
print(pageNo, pageName)
for article in page["articleList"]:
title = article["title"]
subtitle = article["subtitle"]
pid = article["id"]
url = "https://www.shobserver.com/staticsg/data/journal/" + year + '-' + month + '-' + day + "/" + str(pageNo) + "/article/" + str(pid) + ".json"
print(pid, title, subtitle)
html = fetchUrl(url)
cont = json.loads(html)["article"]["content"]
bsobj = bs4.BeautifulSoup(cont, 'html.parser')
content = title + subtitle + bsobj.text
print(content)
path = destdir + '/' + year + month + day + '/' + str(pageNo) + " " + pageName + "/"
fileName = year + month + day + '-' + pageNo + '-' + str(pid) + "-" + title + '.txt'
saveFile(content, path, fileName)
if __name__ == '__main__':
'''
主函数:程序入口
'''
# 爬取指定日期的新闻
newsDate = input('请输入要爬取的日期(格式如 20210416 ):')
year = newsDate[0:4]
month = newsDate[4:6]
day = newsDate[6:8]
download_jfrb(year, month, day, 'Data')
print("爬取完成:" + year + month + day)以上是爬取单天的新闻文章的爬虫,如果希望爬取一段时间内的新闻文章数据,可以参照《Python 网络爬虫实战:爬取人民日报新闻文章》中的代码进行修改。
三、运行效果
运行程序,输入 20210424 以后,爬虫自动爬取了 2021年4月24日的新闻数据,并保存在 Data / 20210424 / 目录下。


如果文章中有哪里没有讲明白,或者讲解有误的地方,欢迎在评论区批评指正,或者扫描下面的二维码,加我微信,大家一起学习交流,共同进步。


