最近想跟女朋友换个情侣头像,找了一圈,终于在 小红书 里找到几个看上眼的,保存图片时,找了半天发现居然没有下载按钮!!!
那可不可以分享呢,复制分享链接在浏览器中打开试了一下,这样可以保存图片了,但是图片是有水印的。
可不可以下载到去水印的图片呢?
我去网上简单搜索了一下,倒是搜到很多去水印的小程序,但是这些几乎都是有免费使用次数限制的,解析几次就不让用了,要充钱或者什么的,作为一名会爬虫的程序员,这能忍?
既然它们可以通过小红书的分享链接直接解析出无水印的图片,那么理论上来讲,我也可以!
话不多说,说干就干。
1. 思路分析
首先,在小红书 APP 中点击分享,获取到它的链接分享,如:https://www.xiaohongshu.com/discovery/item/60a5f16f0000000021034cb4
然后把它在浏览器中(我用的是 chrome 浏览器)打开。

按 F12 或者 Ctrl + shift + i 打开 开发者工具,切换到 Network 类型,过滤器选择 Img,如图所示,

刷新一下网页,可以很轻松的提取到我们要的图片的链接。

在 Preview 中可以预览图片,在 Headers 中可以查看到图片的 请求头 等信息。

如上图,就可以知道图片的下载链接了。
https://ci.xiaohongshu.com/0c7a3f7b-92c9-4e0b-5408-4154abc82d86?imageView2/2/w/100/h/100/q/75
简单分析一下,链接由以下几部分组成,域名(https://ci.xiaohongshu.com/) + 图片id(0c7a3f7b-92c9-4e0b-5408-4154abc82d86) + ? + 压缩格式(imageView2/2/w/100/h/100/q/75)。
Tips:浏览器中直接访问
https://ci.xiaohongshu.com/0c7a3f7b-92c9-4e0b-5408-4154abc82d86?imageView2/2/w/100/h/100/q/75会弹出下载界面;而去掉?后面的部分,访问https://ci.xiaohongshu.com/0c7a3f7b-92c9-4e0b-5408-4154abc82d86会在浏览器中打开图片。

通过上面的链接直接下载到的图片,我们发现是有水印的,那无水印的图片怎么去获取呢?
我们继续分析。
我们已经知道了,图片的链接是由 域名 + ID + 压缩格式 组成的,而后面的压缩格式字段只影响图片的尺寸和质量,并不影响有无水印,甚至去掉都没关系(貌似去掉以后获取到的是压缩前的原图)。
所以,无水印的图片,一定是通过 ID 来控制的。而且作为程序员的直觉,这个无水印图片 ID (如果有的话)一定是跟有水印的图片 ID 放一起的。
接下来,我们复制 0c7a3f7b-92c9-4e0b-5408-4154abc82d86(有水印的图片ID) 去网页源码里搜索,看有无收获。

经过一番寻找,终于找到一个地方很可疑,是一个 json 格式的文本,在 imageList 下有很多元素,每一项里都有 url ,宽高,fieldId,traceId 信息。
我们发现,url 就是我们刚才找到的图片链接(里面的 \u002F 是 斜杠 / 的 URL编码),fieldId 就是我们找到的图片的 ID。
这时候,就有一个字段很可疑了,traceId 是什么呢?
抱着试试的心态,我把 url 里的 图片id 换成了 traceId 的值,复制到浏览器中查看一下
https://ci.xiaohongshu.com/5ab4de05-817e-302f-b2c2-3a7562102b96
嘿,您猜怎么着?水印没啦!!哈哈哈哈

这样,我们就完成了 图片去水印 的思路分析环节,成功提取到了无水印的图片链接。
接下来,我们使用 python 爬虫程序来实现这一过程。
2. 编码环节
整理一下我们的提取思路:
- 找到小红书分享链接的网页源码
- 提取出包含图片信息的
imageList字段,解析为json格式 - 提取出
traceId字段,替换原图片url中的fieldId部分 - 使用新拼接好的
url下载图片
接下来我们编码来实现这一过程。
2.1 网络请求函数
import requests
def fetchUrl(url):
'''
发起网络请求,获取网页源码
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9 ',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36',
'cookie':'你自己的 cookie',
}
r = requests.get(url, headers = headers)
return r.text我们使用 requests 库来发起网络请求,其中,url 是要请求的网址,headers 是请求头,用来把爬虫伪装成浏览器,以及向服务器发送一些必要的参数。
小红书的服务器要验证 cookie 信息,cookie 不填或者过期都会访问失败,所以需要去浏览器中复制自己的 cookie 替换到代码中。
2.2 解析图片链接
def parsing_link(html):
'''
解析html文本,提取无水印图片的 url
'''
beginPos = html.find('imageList') + 11
endPos = html.find(',"cover"')
imageList = eval(html[beginPos: endPos])
for i in imageList:
picUrl = f"https://ci.xiaohongshu.com/{i['traceId']}"
yield picUrl, i['traceId']
这个函数的作用是解析网页源码,从中提取出去水印图片的 url 链接。
这里提取的时候我们没有用第三方解析库,而是取了个巧,大家可以参考一下。

如图所示,我们需要的是图中红框部分的数据,观察后发现,这些数据位于字符串 imageList 和 ,"cover" 之间。
所以使用 .find 函数直接定位起始和终止位置,通过 html[beginPos: endPos] 直接将中间部分提取出来了。
此外,这里的 eval() 函数,作用是把字符串解析成 json 对象。
2.3 下载保存图片
def download(url, filename):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36',
}
with open(f'{filename}.jpg', 'wb') as v:
try:
r = requests.get(url, headers=headers)
v.write(r.content)
except Exception as e:
print('图片下载错误!')这个函数的作用是通过图片链接,下载图片并保存在本地。
保存图片跟保存文本不同的点在于,图片的数据是二进制形式,所以
- 处理网络请求结果时,使用
r.content(普通文本一般用r.text) - 保存文件时,
mode选择wb(普通文本一般用w)
2.4 主函数
if __name__ == '__main__':
original_link = 'https://www.xiaohongshu.com/discovery/item/60a5f16f0000000021034cb4'
html = fetchUrl(original_link)
for url, traceId in parsing_link(html):
print(f"download image {url}")
download(url, traceId)
print("Finished!")主函数作为 爬虫调度器,用来启动爬虫,控制爬虫进度等。
original_link 是初始请求链接,即小红书的分享链接
download(url, traceId) 中,第二个参数是图片保存的文件名,这里我设置了 traceId 作为文件名,大家可以根据需要自行设置命名规则。
3. 运行效果
启动程序,爬虫顺利运行,下面是运行结果。
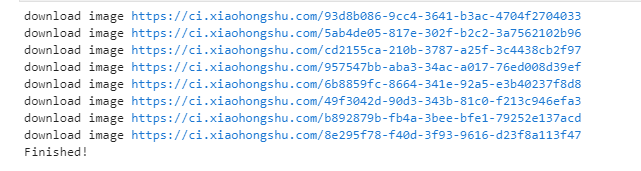
无水印的图片也顺利保存到了本地。
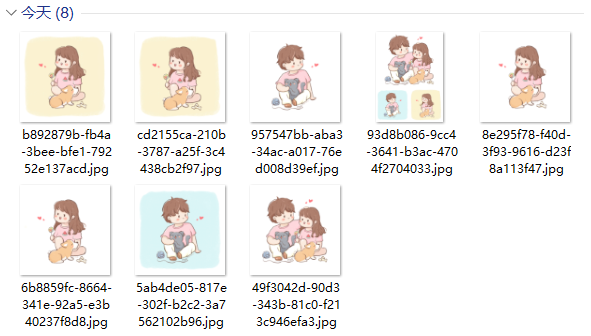
4. 爬虫源码分享
import requests
def fetchUrl(url):
'''
发起网络请求,获取网页源码
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9 ',
'cookie':'你自己的cookie',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36',
}
r = requests.get(url, headers = headers)
return r.text
def parsing_link(html):
'''
解析html文本,提取无水印图片的 url
'''
beginPos = html.find('imageList') + 11
endPos = html.find(',"cover"')
imageList = eval(html[beginPos: endPos])
for i in imageList:
picUrl = f"https://ci.xiaohongshu.com/{i['traceId']}"
yield picUrl, i['traceId']
def download(url, filename):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36',
}
with open(f'{filename}.jpg', 'wb') as v:
try:
r = requests.get(url, headers=headers)
v.write(r.content)
except Exception as e:
print('图片下载错误!')
if __name__ == '__main__':
original_link = 'https://www.xiaohongshu.com/discovery/item/60a5f16f0000000021034cb4'
html = fetchUrl(original_link)
for url, traceId in parsing_link(html):
print(f"download image {url}")
download(url, traceId)
print("Finished!")这下终于可以愉快地跟女朋友换情侣头像了。
如果文章中有哪里没有讲明白,或者讲解有误的地方,欢迎在评论区批评指正,或者扫描下面的二维码,加我微信,大家一起学习交流,共同进步。



大佬 文章中的tarceId 现在已经没有了 还有其他办法么
已失效啊,已失效