中秋节马上到了,不知道大家有没有像我这样的烦恼,每次过节,都要绞尽脑汁想好久,发什么样的祝福语才显得有诚意又有创意,什么样的朋友圈文案会有文化又有逼格。
去网上搜吧,搜出来的祝福语,画风大多是像这样的
佛说:我可以让你许个愿
我对佛说:我愿xxx永远健康,年轻快乐
佛说:只能四天
我说行,春天,夏天,秋天,冬天。
佛说,不行,只能三天。
我说,好,昨天,今天,明天。
佛说,不行,只能两天
我说,好,黑天和白天
佛说,不行,只能一天。
我说,好。
佛茫然地问到,哪一天?
我说,每一天。
又或者是这样的,多少带点年代感。
一帆风顺送给你,二话不说祝福你,三言两语话情谊,四面八方齐祝愿,五光十色属你帅。中秋佳节的到来,发表短信祝愿客户的事业蒸蒸日上,家庭和和美美,身体健健康康。
那有没有适合年轻人的,有诚意有创意有逼格有文化的,优雅而清新脱俗的中秋节文案呢?
我决定用爬虫采集来看看,别人都是怎么发的。
1. 确定爬虫目标
我在各大网站上找了好久,发现很少有这种中秋祝福语文案的板块,而那些祝福语主题的网站,上面的文案还停留在短信祝福的年代,读起来浑身的鸡皮疙瘩。
找了一圈,我还是把目光放回了知乎,在一些关于中秋节文案的问题下,还是有不少高质量的回答的。
此外,我还发现,也有不少专栏文章整理了很多很棒的中秋节祝福文案。


所以,我们爬虫的目标分为两部分,一部分是爬取知乎问题下的回答,另一部分是爬取知乎专栏的文章内容。
2. 爬虫部分
我们爬虫的目标有两部分,一部分是爬取知乎问题下的回答,另一部分是爬取知乎专栏的文章内容。
2.1 爬取问题回答
2.1.1 网页分析
由于此前我们在文章《Python网络爬虫实战:爬取知乎话题下 18934 条回答数据》中已经详细讲解了如何爬取知乎问题下的全部回答数据,想了解我们如何抓包获取数据接口的朋友,可以去这里查看。
所以这里网站接口分析部分跳过,直接上代码!
2.1.2 爬虫源码
import requests
from bs4 import BeautifulSoup
import json
def fetchUrl(url):
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get(url, headers=headers)
return r.json()
def parse_Json(jsonObj):
json_data = jsonObj['data']
try:
for item in json_data:
qid = item['question']['id']
content = item['content']
bsObj = BeautifulSoup(content, "html.parser");
lines = bsObj.find_all("p")
for line in lines:
sts = line.text.replace(" ", "");
if len(sts) > 3:
save_data(qid, sts + "\n");
print(sts)
print("----------" * 20)
except Exception as e:
print(e)
def save_data(qid, data):
filename = f'{qid}.txt'
with open(filename, "a") as f:
f.write(data)
def getMaxPage(qid):
url = f"https://www.zhihu.com/api/v4/questions/{qid}/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cvip_info%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled&limit=5&offset=0&platform=desktop&sort_by=default"
jsObj = fetchUrl(url)
totals = jsObj['paging']['totals']
print(totals)
print('---'*10)
return totals
if __name__ == '__main__':
# 这里设置问题的id
qid = 25252525;
maxPage = getMaxPage(qid);
page = 0
while(page < maxPage):
url = f"https://www.zhihu.com/api/v4/questions/{qid}/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cattachment%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Cis_labeled%2Cpaid_info%2Cpaid_info_content%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_recognized%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cvip_info%2Cbadge%5B%2A%5D.topics%3Bdata%5B%2A%5D.settings.table_of_content.enabled&limit=5&offset={page}&platform=desktop&sort_by=default"
print(url)
jsonObj = fetchUrl(url)
parse_Json(jsonObj)
page += 5
print("完成!!")设置好要爬取的问题id(即代码中的 qid)后,运行代码即可爬取。
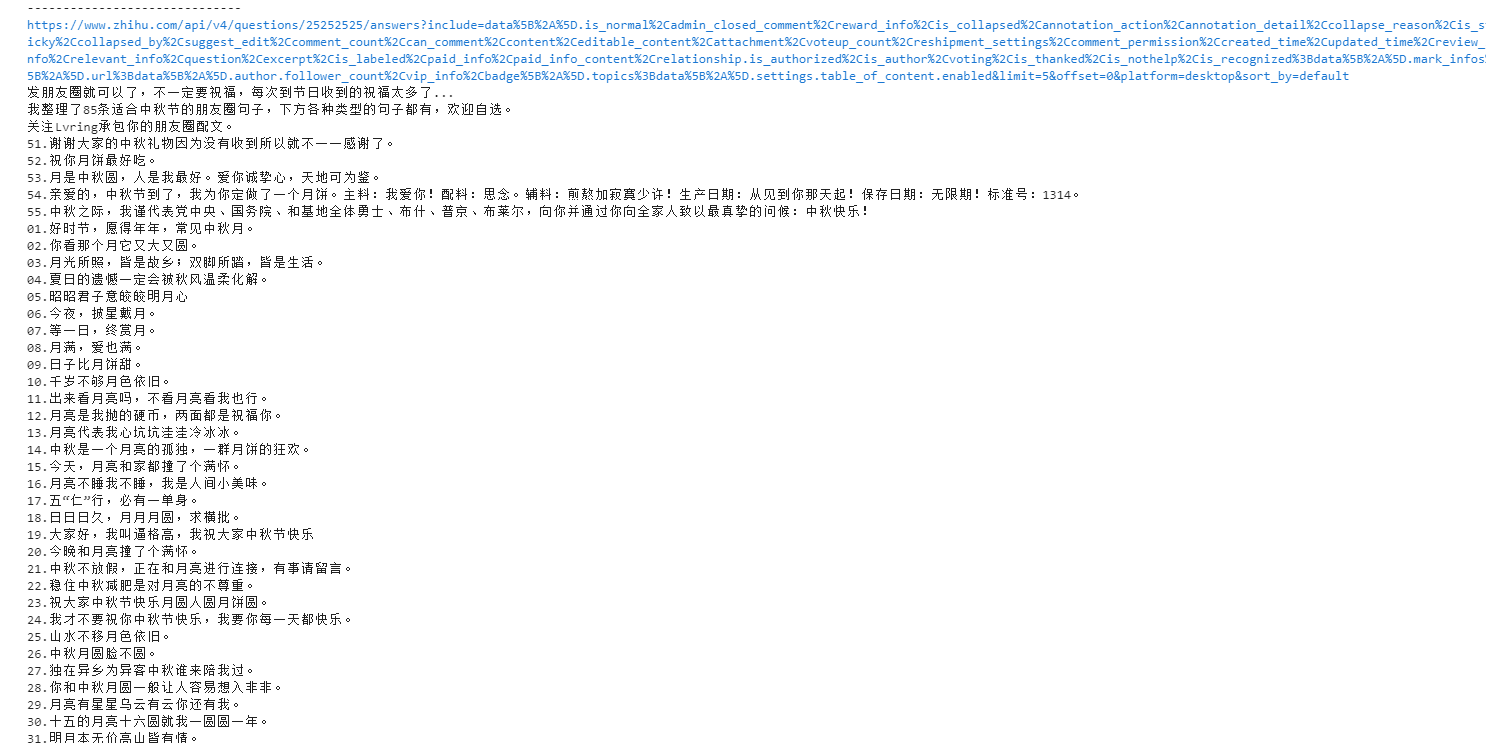
2.1.3 运行效果
2.2 爬取专栏文章
相比之下,专栏文章的爬取就简单很多了。
2.2.1 网页分析
首先,我们打开 F12 开发者工具 后刷新网页,在 Preview 里可以查看到,文章正文数据直接在网页源码中,不需要额外的接口获取。
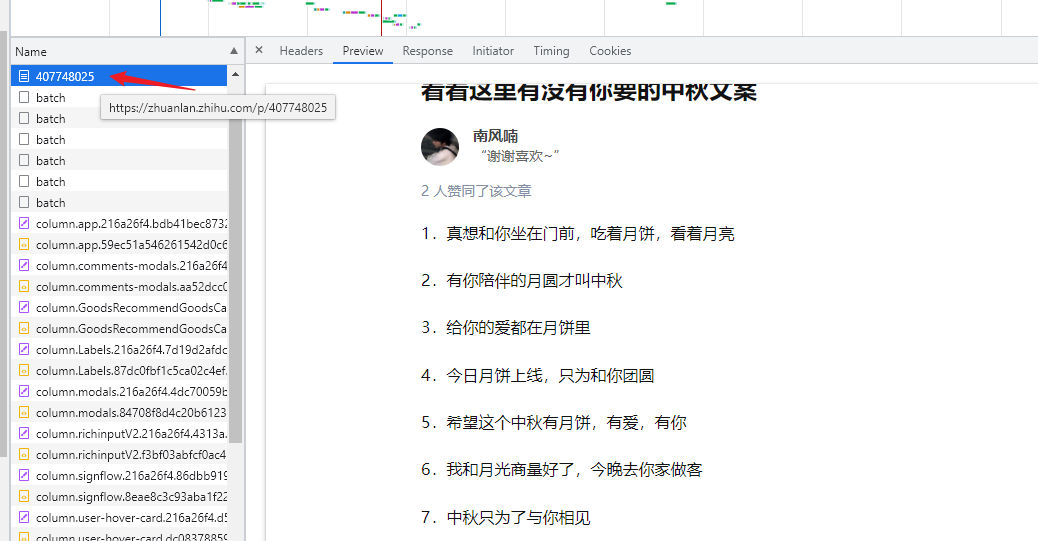
也就是说,我们不需要抓包,直接解析网页 HTML 文本即可。
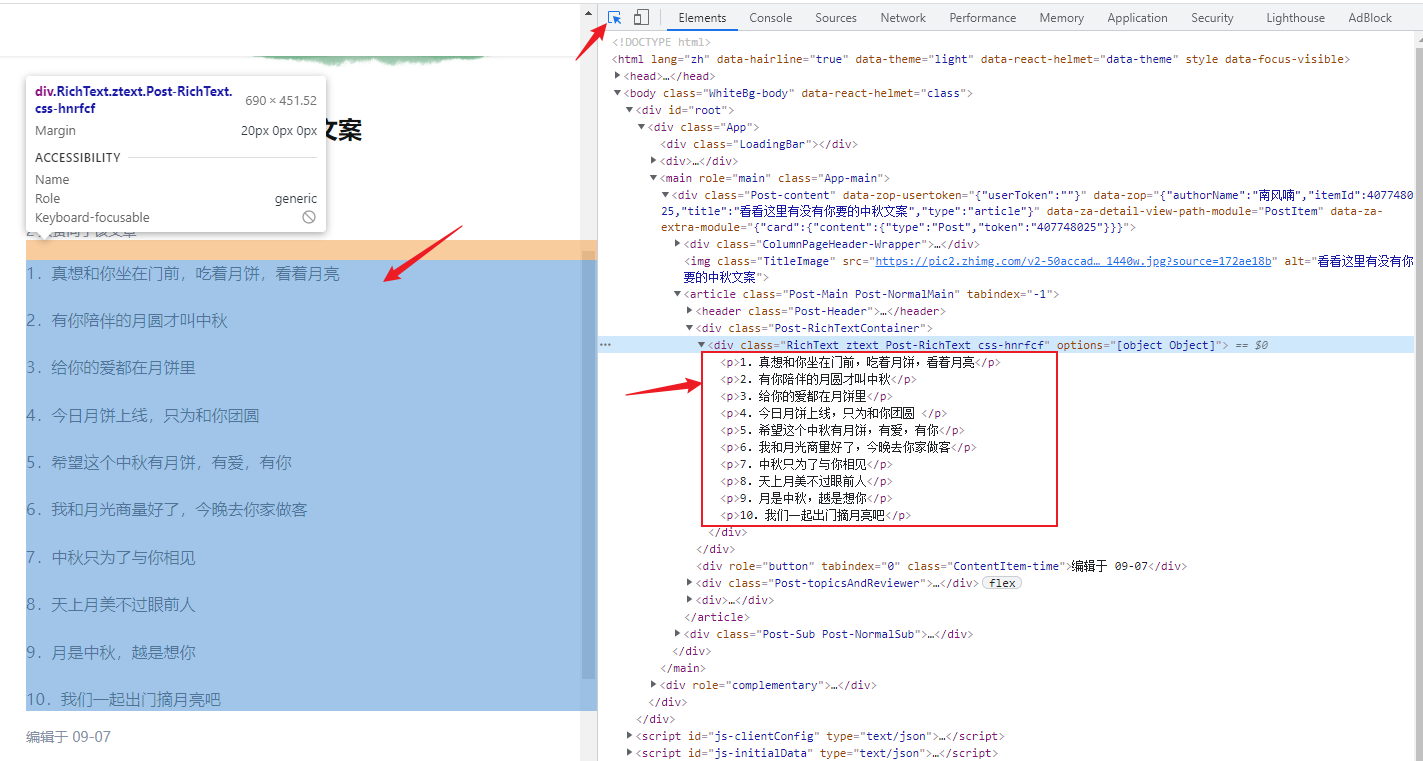
开发者工具切换到 Elements 页签,找到文章正文所在的标签。
Tips: 点击一下左上角的箭头,然后再点一下网页中正文的位置,这样开发者工具会自动定位到你点击的网页位置,所对应的源码部分,非常方便。
这样我们就知道了,正文内容是位于一个 class 为 Post-RichText 的 div 标签下,每一段文字都位于一个 p 标签中。
用以下的方式就可以完成正文内容的提取。
from bs4 import BeautifulSoup
bsObj = BeautifulSoup(html, "html.parser");
richText = bsObj.find("div", attrs={"class": "Post-RichText"});
lines = richText.find_all("p")最后上代码!
2.2.2 爬虫源码
import requests
from bs4 import BeautifulSoup
import json
def fetchUrl(url):
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get(url, headers=headers)
return r.text
def parse_Html(html):
bsObj = BeautifulSoup(html, "html.parser");
richText = bsObj.find("div", attrs={"class": "Post-RichText"});
lines = richText.find_all("p")
for line in lines:
sts = line.text.replace(" ", "");
if len(sts) > 3:
save_data("zhuanlan", sts + "\n");
print(sts)
# print(richText)
def save_data(qid, data):
filename = f'{qid}.txt'
with open(filename, "a") as f:
f.write(data)
if __name__ == '__main__':
# 专栏文章 id 列表
pidList = [407748025, 250353160, 259765710, 82196621, 82400827];
for pid in pidList:
url = f'https://zhuanlan.zhihu.com/p/{pid}'
print(url)
html = fetchUrl(url)
parse_Html(html)
print("------" * 20)
print("完成!!")2.2.3 运行效果

3. 数据分析部分
我挑选了与 中秋节祝福文案 相关的 3 个问题,和 5 篇专栏文章进行爬取,爬取结果为一千三百多行。
3.1 数据预处理
如图所示, 其中夹杂着很多 如分割线啊,开场白啊,讲故事之类与祝福语文案无关的句子,需要进行数据清洗。

处理过程简单来说就是,先手动删除无关的句子之后,再通过代码处理成统一格式,最后去重。
最终经过数据清洗,得到的祝福语条数为 873 条。

3.2 网页展示
得到了这么多数据之后,我们当然不满足于此,那接下来做什么呢?怎么展示我们的数据呢?
我突然想起了来,之前在网上火过一段时间的一个开源项目《舔狗日记》。
貌似也没有什么版权问题,于是在此基础上,我简单修改了一下,得到了我的《中秋日记》。
演示网址:http://api.smartcrane.tech/Mid-Autumn/
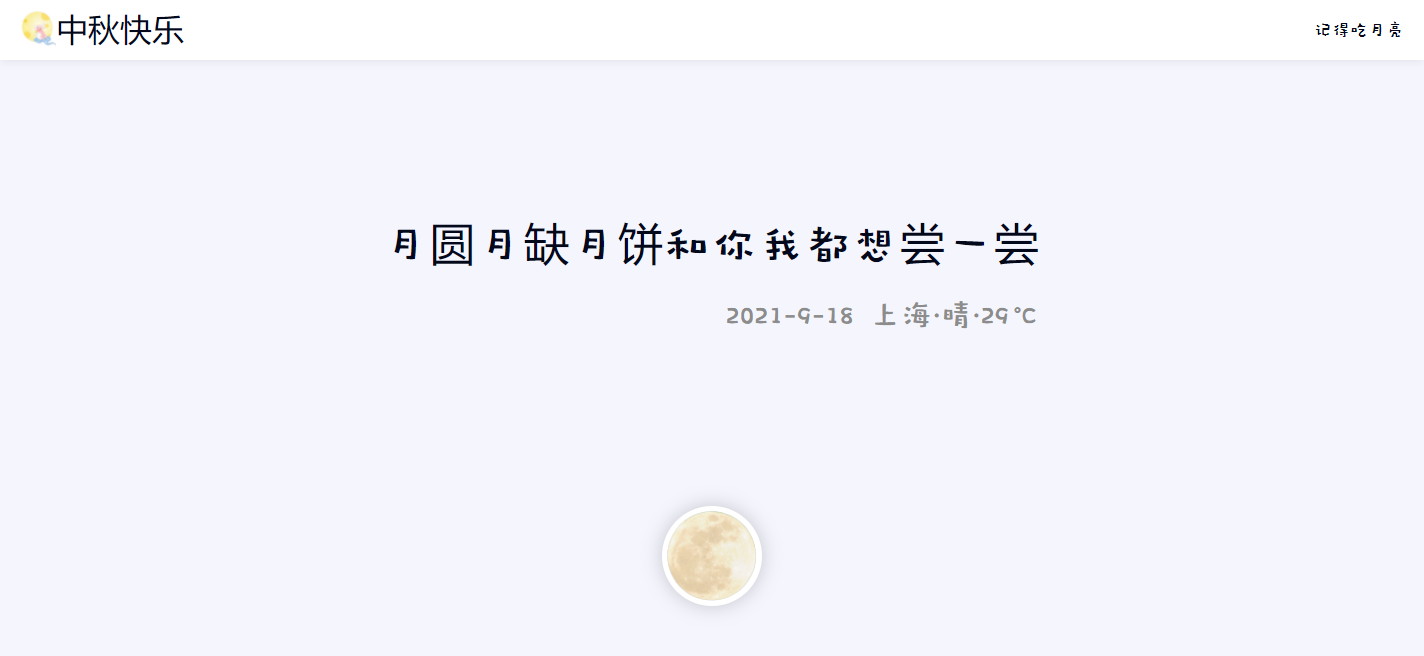
如果有对项目源码感兴趣,或者想在此基础上自己
DIY的朋友,可以私信找我要源码哦。
后记
这次我们爬取了知乎上 873 条有诚意又有创意,有文化又有逼格的中秋节祝福文案,然后我们还为这些数据做了一个蛮精致的小网页进行展示。
相信到时候亲朋好友们收到这样的祝福,一定能感受到你满满的诚意吧。
不过话说回来,祝福语说的再好,还不如发个红包来的实在。
祝大家中秋节快乐!记得吃月亮哦
如果文章中有哪里没有讲明白,或者讲解有误的地方,欢迎在评论区批评指正,或者扫描下面的二维码,加我微信,大家一起学习交流,共同进步。


