在使用爬虫程序下爬数据时候,经常会遇到 乱码 的问题,那遇到乱码该怎么办呢?
一般大家看到乱码,下意识的觉得会不会是爬虫爬错东西了?其实没有,这个就是简单的编码的问题。
一般在爬虫程序中,涉及到编码格式的地方有两处,一处是在发起请求后,对返回的内容进行解码;另一处是在保存文件时,设置编码格式。下面我们分开来说。
1. 发起请求,获取网页内容阶段
一般的网站的编码格式都是 UTF-8,所以当你系统的默认编码也是 UTF-8 时,也就是说,你的默认编码方式和目标网站的编码方式一致时,即使不明确设置编码方式,也不会出问题。
但是如果不一致,便会出现乱码。这也是为什么经常有 明明在我电脑上运行是好的,为什么在你电脑上就乱码了 这样的问题。这种问题解决也很简单,只要在代码中设置一下 encoding 即可。
这里建议一种方法,r.encoding = r.apparent_encoding ,这个可以自动推测目标网站的编码格式,省的你自己去一个个设置(当然极少数情况下它可能会推测错误出现乱码,到时候你再手动去查看网页编码,手动设置吧)。
def fetchURL(url):
headers = {
'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get(url,headers=headers)
# 这里设置编码格式
r.encoding = r.apparent_encoding
return r.text2. 保存文件时的编码错误
这个是读者朋友们反映较多的一个问题,就是爬取过程中没问题,但是用 excel 打开保存好的 csv 文件时出现乱码(用记事本打开没问题),这个其实就是文件的编码方式和 Excel 的解码方式不一致导致的。
在 dataframe.to_csv 这句,参数里添加一个 encoding='utf_8_sig',指定文件的编码格式,应该就可以解决了。
import pandas as pd
def writePage(urating):
'''
Function : To write the content of html into a local file
'''
dataframe = pd.DataFrame(urating)
dataframe.to_csv('filename.csv',encoding='utf_8_sig', mode='a', index=False, sep=',', header=False )之前乱码的 csv 文件,可以用记事本打开,然后点另存为,然后选择编码格式,ANSI ,unicode,UTF-8 都可以,然后保存之后,再次用 excel 打开就是正常的了。
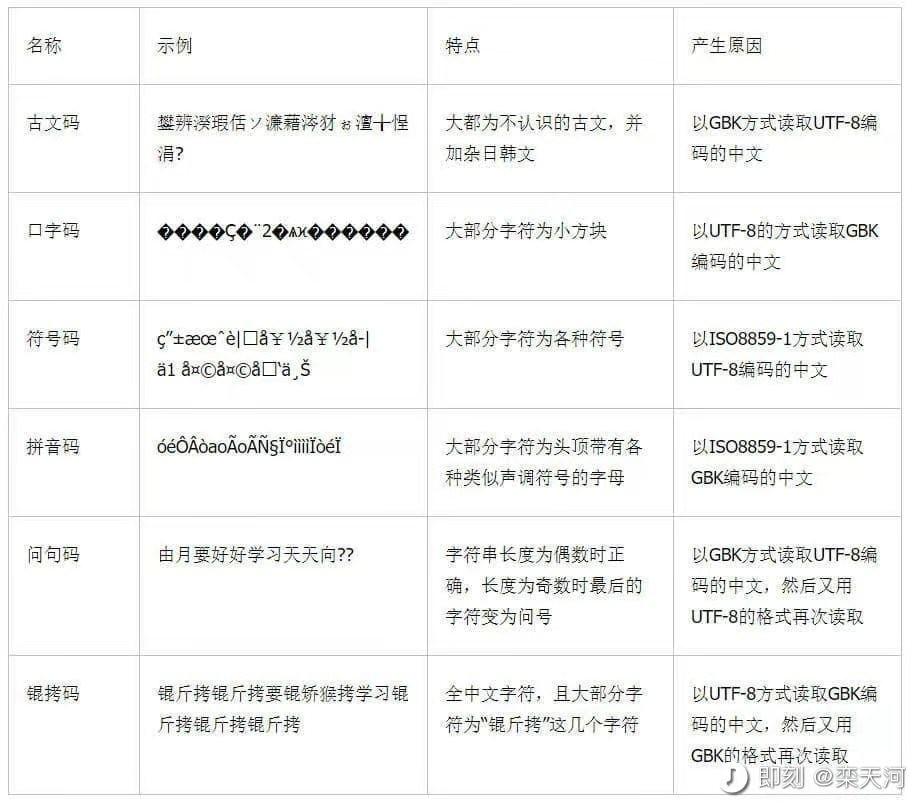
3. 常见乱码类型
常见的乱码情况有以下几种,大家可以参考一下。