BS4 全称是 BeatifulSoup,它提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。我们可以通过它很方便的完成爬虫中的 html 解析工作。
本文简单介绍一些 bs4 里常用的函数,可以应付大多数的情况。
1. 定位标签
首先,爬取之前需要定位到数据所在的标签,这个使用 F12 开发者工具中的这个按钮,点一下按钮,然后点一下网页,可以很快定位到页面中的相应标签,具体就不详细说了,自己摸索一下,很简单,很好用的。

接下来正式介绍,如何用代码获取到前面找到的那个标签。
这里介绍 BeautifulSoup 中的两个函数,find() 和 find_all() 函数。
首先你观察你要找到的标签,是什么标签,是否有 class 或者 id 这样的属性(如果没有就找找它父标签有没有,尽量找这样的),因为 class 和 id 这两个属性作为筛选条件的话,查找到的干扰项极少,运气好的话,基本上可以一击必中。
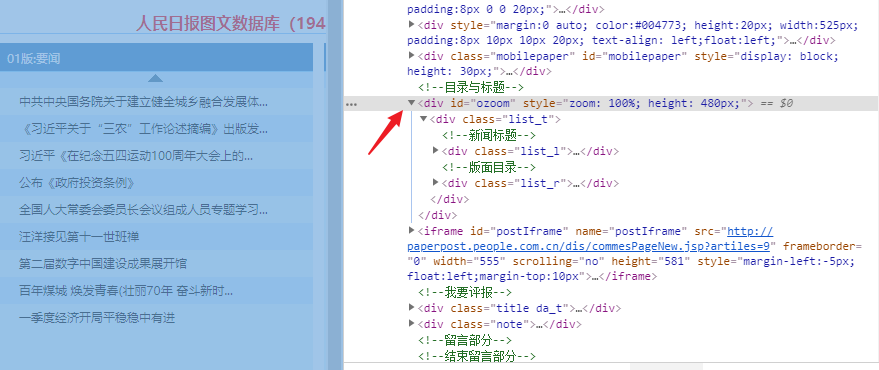
比如上图中箭头所指的,id 为 ozoom 的 div 标签时,我们可以这样来获取
# html 是之前发起请求获取到的网页内容
bsobj = bs4.BeautifulSoup(html,'html.parser')
# 获取 id 为 ozoom 的 div 标签
# 根据 id 查找标签
div = bsobj.find('div', attrs = {'id' : 'ozoom'})
# 继续获取 div 下的 class 为 list_t 的 div 标签
# 根据 class 查找标签
title = div.find('div', attrs = {'class': 'list_t'})注:如果标签有 id 属性的话尽量用 id 来查找,因为整个页面 id 是唯一的。用 class 查找的话,最好现在浏览器的网页源码中 Ctrl + F 搜索一下,相同 class 的标签有多少(如果比较多的话,可以尝试先查找他的父标签,缩小范围之后再查找)。
然后我们再讲讲 find_all 函数,适用于一次性查找一类型的很多标签的情况,比如下图这种情况。
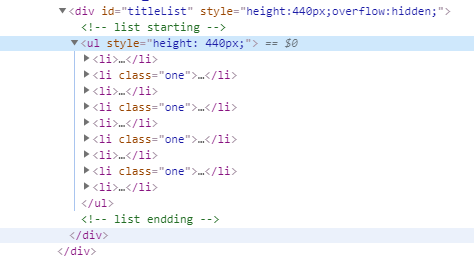
列表中的每一个 li 标签中,都是一条数据,我们需要将它们都获取到,如果是用前面的 find 函数的话,每次只能获取一个 li 标签。所以我们需要使用 find_all 函数,一次性获取所有符合条件的标签,存储为数组返回。
首先,由于 li 标签没有 id 也没有 class ,而页面中存在很多无关的干扰的 li 标签,所以我们需要先从它的父标签往上找,缩小查找范围,找到 id 为 titleList 的 div 标签之后,观察一下,里面的 li 标签都是需要的,直接 find_all 函数一下都获取完。
# html 是获取的目标网页内容
html = fetchUrl(pageUrl)
bsobj = bs4.BeautifulSoup(html,'html.parser')
pDiv = bsobj.find('div', attrs = {'id': 'titleList'})
titleList = pDiv.find_all('li')基本上,把 find 和 find_all 函数组合使用,用熟练了可以应付几乎所有的 html 网页了,真的是,一招鲜吃遍天。
2. 提取数据
查找到标签之后,我该如何获取标签中的数据呢?
标签中的数据位置,一般有两种情况。
<!--第一种,位于标签内容里-->
<p>这是数据这是数据</p>
<!--第二种,位于标签属性里-->
<a href="/xxx.xxx_xx_xx.html"></a>如果是第一种情况,很简单,直接 pTip.text 即可(pTip 是前面已经获取好的 p 标签)。
如果是第二种情况,需要看它是在哪一个属性里的数据,比如我们要获取上面 a 标签中的 href 属性中的链接,通过 link = aTip["href"] 即可。(aTip 是前面已经获取好的 a 标签)。

