在使用爬虫时候,经常需要构造请求头 Headers ,将爬虫伪装成浏览器来绕过反爬机制,根据目标网站服务器的反爬机制不同,我们经常需要构造的请求头参数有 Accept , User-Agent ,Cookie 等,如果每次爬取都需要手动逐项复制粘贴,未免太过繁琐。
本文提供了一个简单的 python 小脚本,可以将浏览器中的 headers 部分一键格式化,可以极大的方便我们写爬虫时的工作。
代码如下:
import re
headerStr = '''
浏览器中的请求头复制到这里
'''
ret = ""
for i in headerStr:
if i == '\n':
i = "',\n'"
ret += i
ret = re.sub(": ", "': '", ret)
print(ret[3: -3])使用时候,将开发者工具抓到的包的 Request Headers 全选复制粘贴到代码中的 headerStr 处。
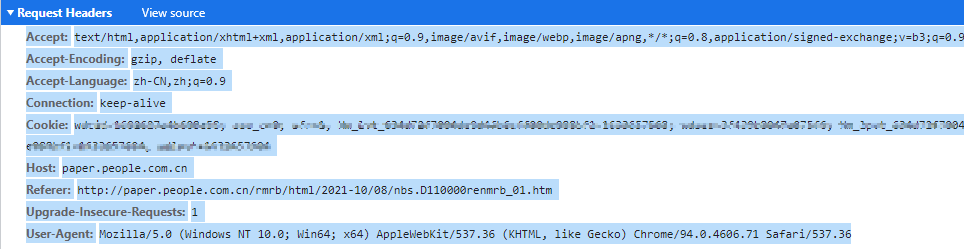
如下所示
import re
headerStr = '''
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Connection: keep-alive
Cookie: *******
Host: paper.people.com.cn
Referer: http://paper.people.com.cn/rmrb/html/2021-10/08/nbs.D110000renmrb_01.htm
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36
'''
ret = ""
for i in headerStr:
if i == '\n':
i = "',\n'"
ret += i
ret = re.sub(": ", "': '", ret)
print(ret[3: -3])运行代码后,会打印出格式后的 Headers 字符串,可以直接放到代码中使用,非常方便。


