平时逛知乎的时候,经常能看到很多很棒的图片,精美的壁纸,搞笑的表情包,有趣的截图等等,总有想全部保存下来的冲动。
于是在一个小老弟的拜托之下,我把之前的知乎爬虫改造了一下,改装成了一个可以下载知乎回答中全部图片的新爬虫。
1. 分析网站
知乎的网站我们已经爬取过很多次了
《Python 网络爬虫实战:爬取知乎一个话题下的全部问题》
《Python网络爬虫实战:爬取知乎话题下 18934 条回答数据》
《Python网络爬虫实战:近千条中秋节祝福语文案让你成为亲朋好友里最靓的仔》
所以,网站分析的抓包过程我们就简单讲解,不太过详细的赘述了(如果有想要了解的同学,可以去之前的文章中查看)。
本文我们以知乎问题《有哪些好看的电脑壁纸值得分享》为例,进行爬虫讲解。
示例网址:https://www.zhihu.com/question/316039999
经过之前的分析,我们知道,知乎网站的回答数据,是通过 Ajax 动态加载的,每次页面划到底部时,请求新的5条数据进行加载,接口如下图所示。
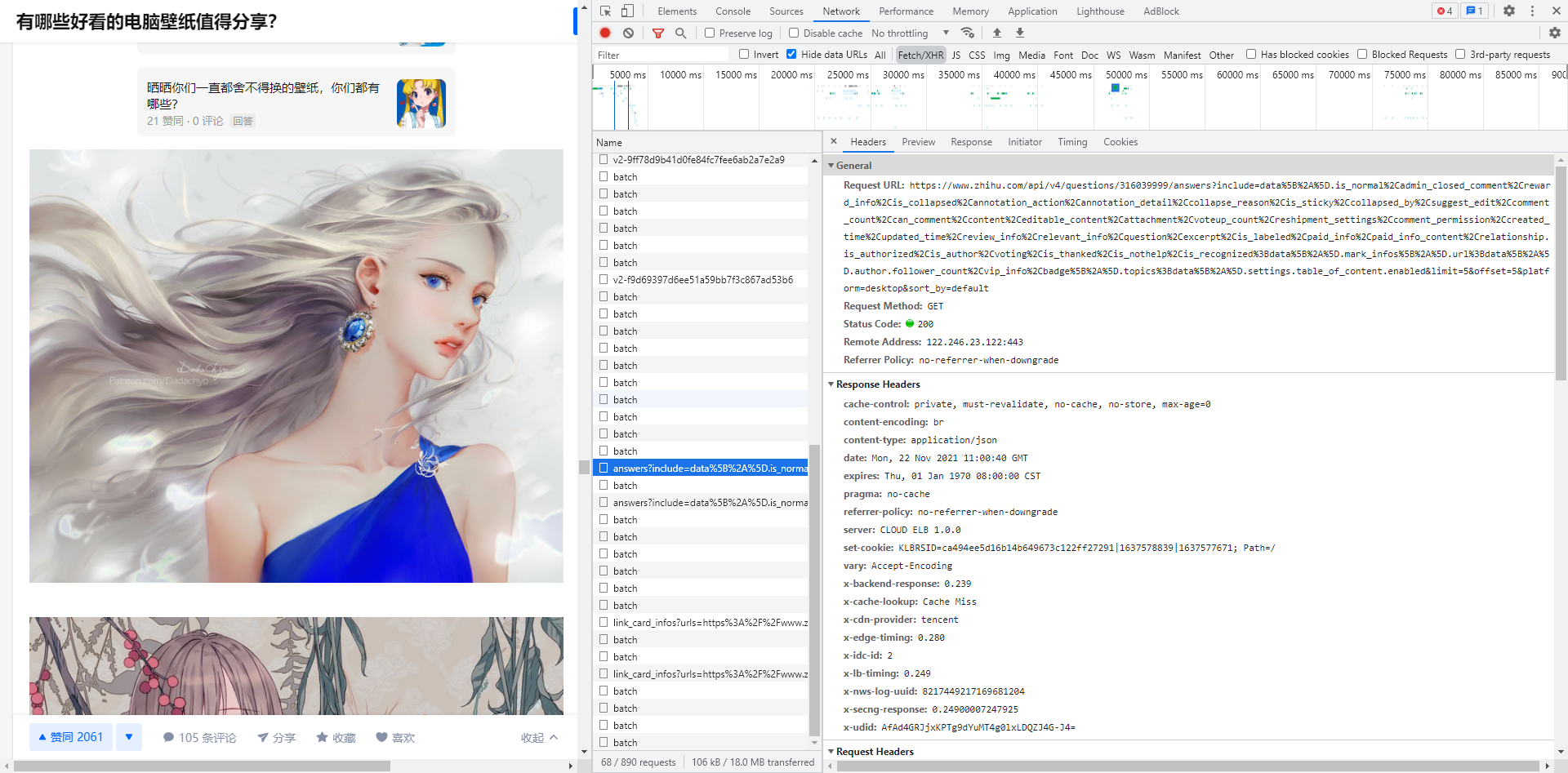
参数有 4 个,include 参数控制向服务器请求哪些数据,limit 参数控制每次请求多少条数据,offset 参数控制偏移量,也就是页数,sort_by 参数控制排序方式。
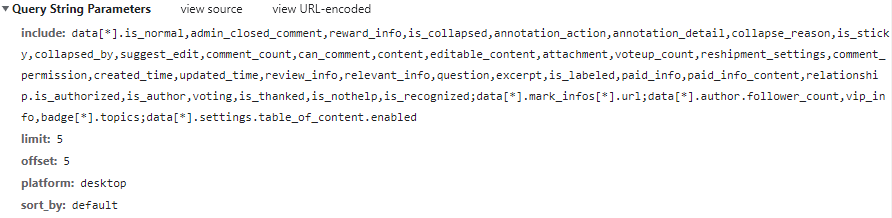
在我们的爬虫中,只需要更改 offset 来控制爬取的页数即可,其他可以保持不变。

该接口返回的数据是 Json 格式的,其中回答内容位于 data[i] --> content 中,以 html 格式存储。
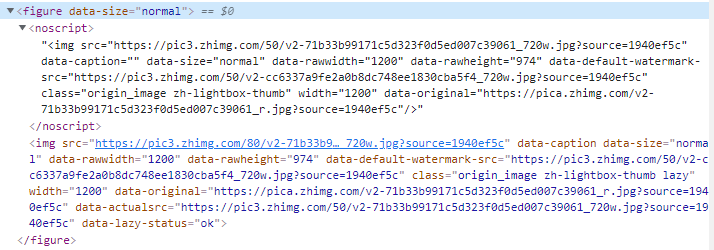
将其格式化后发现,图片位于 img 标签中,图片链接为 src 属性。
不过,奇怪的是,它同一张图片,用了两个一模一样的
img标签,其中一个位于noscript标签下。(我没太清楚这样做的用意,如果有人知道的话,可以在评论区分享一下)
此外,在查看网站分析过程中,我发现通过 img["src"] 获取到的图片链接并不是原始图片。
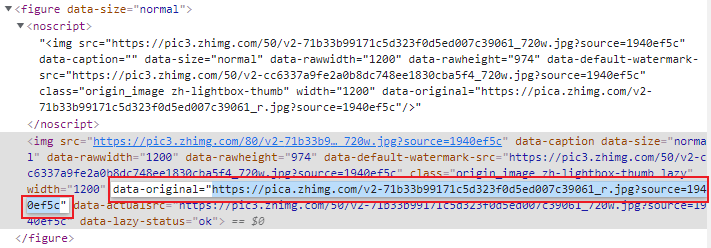
而原始图片链接在 data-original 属性中。
是否要下载原始图片,视自己需求而定。
2. 编码环节
分析完成之后,接下来进入编码环节。
首先,导入需要用到的库
from bs4 import BeautifulSoup
import pandas as pd
import requests
import json
import time
import os用于发起网络请求的 fetchUrl 函数。
def fetchUrl(url):
header = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36',
}
r = requests.get(url, headers=header)
r.encoding = "utf-8"
return r用于解析 Json 格式的接口数据的 parseJson 函数。
它会将每次请求得到的 5 条回答的数据进行解析,得到 作者昵称,个性签名 ,发布日期,点赞数,评论数,回答内容 的数据,并依次返回。
def parseJson(jsonStr):
jsonObj = json.loads(jsonStr)
data = jsonObj['data']
for item in data:
name = item["author"]["name"]
print("正在爬取", name, "的回答")
headline = item["author"]["headline"]
dateTIme = time.strftime("%Y-%m-%d", time.localtime(item['updated_time']))
comment_count = item['comment_count']
voteup_count = item['voteup_count']
content = parseHtml(item["content"])
# print(name, headline, dateTIme, comment_count, voteup_count, content)
yield [[name, headline, dateTIme, comment_count, voteup_count, content]]
用于解析 Html 格式的回答内容数据的 parseHtml 函数。
它会解析每条回答内容,若检测到图片标签,则下载图片,剩余文本部分解析成纯文本字符串返回。
def parseHtml(html):
bsObj = BeautifulSoup(html, "lxml")
images = bsObj.find_all("noscript")
if(len(images) == 0):
print("回答内容无图片")
else:
print("回答中共有",len(images),"张图片,正在下载……")
for item in images:
link = item.img['data-original']
downloadImage(link, "Images/")
print("图片下载完成")
return bsObj.text下载图片的 downloadImage 函数。
def downloadImage(url, path):
bytes = fetchUrl(url).content
# url : https://pic3.zhimg.com/c7ad985268e7144b588d7bf94eedb487_r.jpg?source=1940ef5c
# filename: c7ad985268e7144b588d7bf94eedb487_r.jpg
filename = url.split("?")[0].split("/")[-1]
# 如果没有该文件夹,则自动生成
if not os.path.exists(path):
os.makedirs(path)
with open(path + filename, "wb+") as f:
f.write(bytes)保存 csv 文本的 saveData 函数,用于保存回答数据。
def saveData(data, filename):
dataframe = pd.DataFrame(data)
dataframe.to_csv(filename, mode='a', index=False, sep=',', header=False, encoding="utf_8_sig")以及,主函数,用于程序入口和爬虫调度。
if __name__ == "__main__":
# 保存的文件名
filename = "data.csv"
qid = 316039999
offset = 0
totalNum = 50
while offset < totalNum:
url = "https://www.zhihu.com/api/v4/questions/{0}/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%2Cis_recognized%2Cpaid_info%2Cpaid_info_content%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics&limit=5&offset={1}&platform=desktop&sort_by=default" .format(qid, offset)
html = fetchUrl(url).text
for data in parseJson(html):
# print(data)
saveData(data, filename)
offset += 1
print("已经爬取完成",offset,"条回答数据,一共有",totalNum, "条")
print("---"*20)其中,filename 为存储回答数据的 csv 文件名,qid 为要爬取的知乎问题的 id,offset 和 totalNum 用于控制爬虫的起始页和终止页数。
3. 运行结果和总结
3.1 运行结果
运行程序,爬取一段时间后。
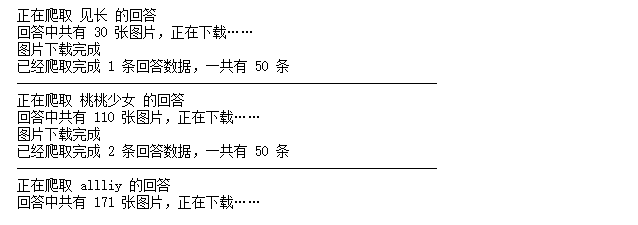
程序运行输出结果
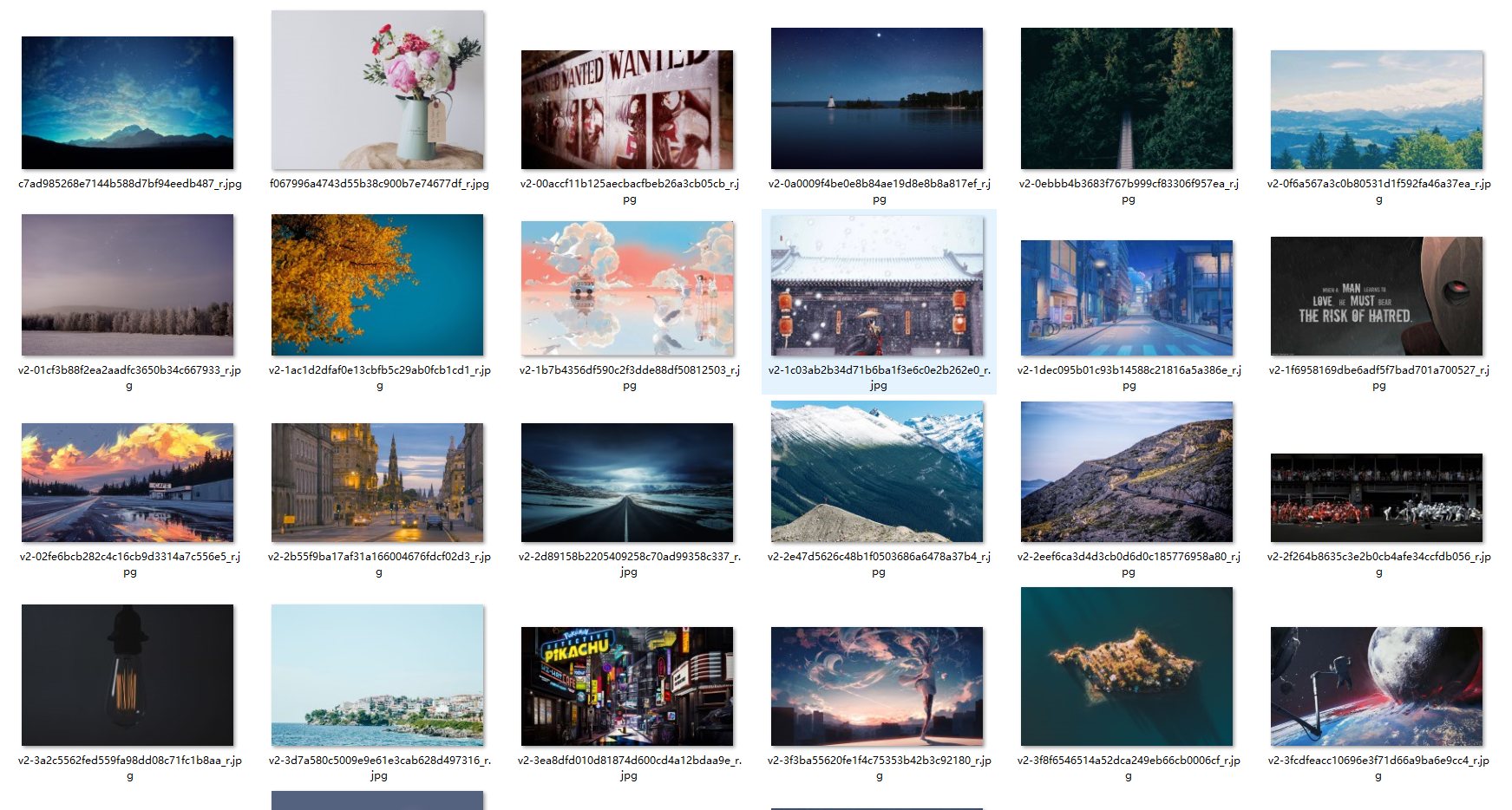
爬取到的图片。
3.2 总结和改进
在本文中,我们完成了下载知乎回答中全部图片(原图)的爬虫,并附上了全部的爬虫代码。
不过该爬虫代码仍然有很多地方可以改进。
3.2.1 代码健壮性不够
为了快速实现爬虫功能,以及降低新手阅读代码的难度,很多容易出错的地方都没有做判断检查,这就容易导致程序健壮性不够,容易崩溃。
举个例子,在前面 parseHtml 函数中,解析图片链接的部分。
for item in images:
link = item.img['data-original']
downloadImage(link, "Images/")
print("图片下载完成")这样写,正常情况下是没问题的
但是爬取没一会儿,可能就会报错,造成程序崩溃退出。
<img class="content_image" data-rawheight="34" data-rawwidth="40" data-size="normal" src="https://pic2.zhimg.com/50/v2-56d491ec13d5b3ad6c1c1bd40ad9f0a5_720w.jpg?source=1940ef5c" width="40"/>因为有的 img 标签中,并没有 data-original 属性。
正确的做法是,在容易出错的代码周围,用 try ... except ... 包围,进行异常捕获和处理。如:
for item in images:
try:
link = item.img['data-original']
downloadImage(link, "Images/")
except:
print(item.img)
print("图片下载完成")这样程序的鲁棒性就会比较高,没那么容易崩溃了。
3.2.2 爬取效率太低
为了降低代码阅读难度,本篇爬虫的代码采用单线程进行爬取。
爬虫获取下一条回答数据,需要等前一条回答中的全部图片下载完成才能进行。
当某类问题回答中图片数量较多时,爬取效率会非常慢。
可以采用多线程的方式,对爬虫程序进行改造。
- 首先将
爬取回答数据和下载图片这两部分的任务拆分开。前者仅负责将解析到图片链接存入数组,而不需要等待图片下载完成;后者仅负责从数组里取链接下载图片,而不必关心链接从何而来。 - 下载图片部分可以改造成多线程,增加爬取速率。
3.2.3 自动跳过已下载的图片
在爬取的过程中,可能会因为各种各样的因素导致爬虫退出,如果重新爬取的话,图片需要从头开始重新下载,浪费不必要的工作和时间。
所以我们可以在保存图片之前,先读取本地是否有该图片,若有,则跳过,若没有,则下载。
def downloadImage(url, filename, path):
bytes = fetchUrl(url).content
# 如果没有该文件夹,则自动生成
if not os.path.exists(path):
os.makedirs(path)
with open(path + filename, "wb+") as f:
f.write(bytes)
for item in images:
try:
link = item.img['data-original']
filename = + url.split("?")[0].split("/")[-1]
if not os.path.exists(path + filename):
# 路径中不存在该图片时再下载
downloadImage(link, "Images/", filename)
except:
print(item.img)如果文章中有哪里没有讲明白,或者讲解有误的地方,欢迎在评论区批评指正,或者扫描下面的二维码,加我微信,大家一起学习交流,共同进步。


