大家好,我是机灵鹤。
今天是跟女朋友在一起 10 个月的纪念日,作为一名会 Python 的程序员,我决定将和女朋友的聊天记录导出来,生成一份专属于我们的《2021 恋爱年度报告》。
感兴趣的朋友也可以学起来。
废话不多说,直接进入正题。
0. 导出聊天记录
由于破解微信聊天数据库的操作相对比较敏感,感兴趣的朋友可以移步《》。
经过一系列操作,我从微信数据库中导出了跟女朋友的聊天记录。
聊天记录数据表 message.csv 格式如下。
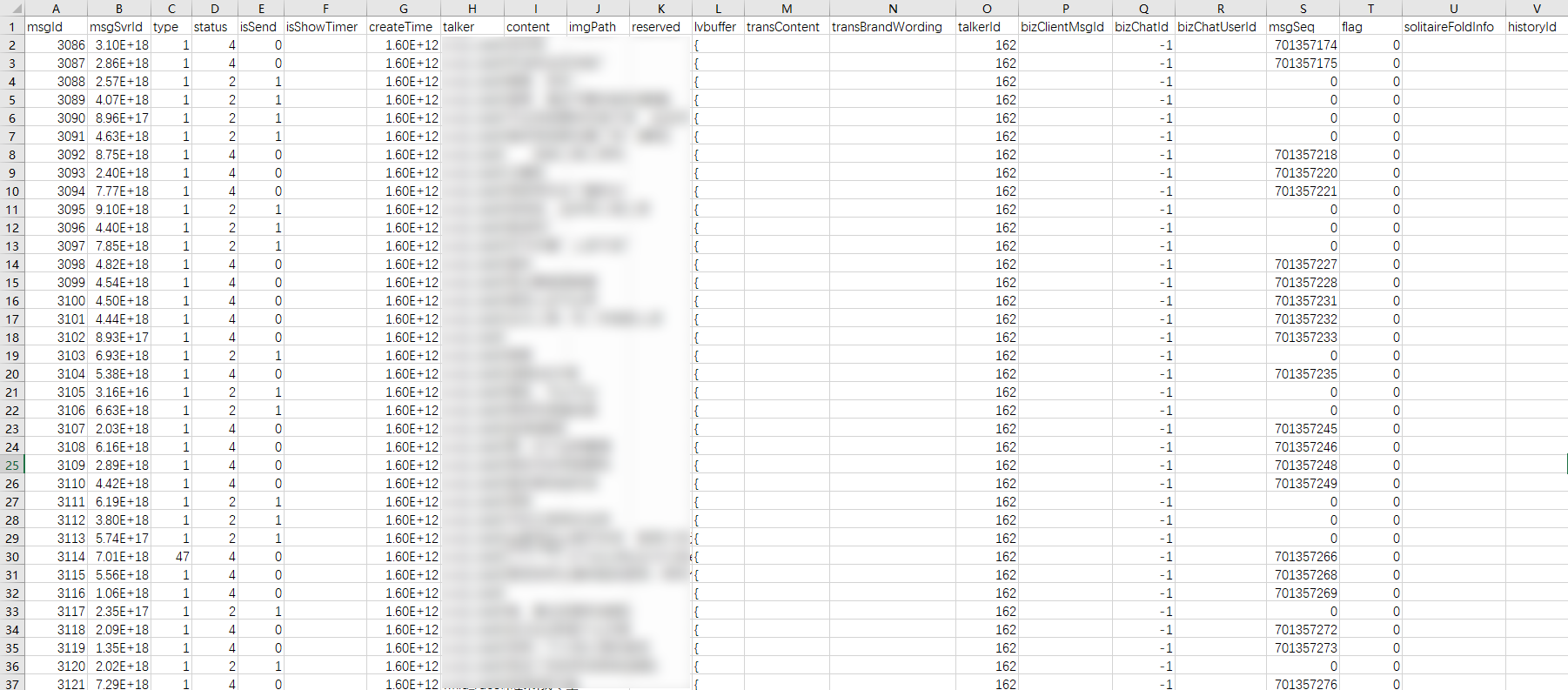
其中,我们只需要关注以下几列即可。
- type :消息类型,如 1 表示文字,3 表示图片,47 表示表情包
- status :消息状态,2 表示发送的消息,4 表示接收的消息
- createTime :发送时间,毫秒级时间戳
- content :消息内容
- imgPath :图片路径,如果是图片消息,则显示图片的 md5 值
- talkerId :聊天对象的 ID
1. 聊天记录分析
本节中,我会使用 Python 对聊天记录文件进行数据分析,生成数据报告。
首先导入用到的模块,如果没有则需要安装。
# 用于读取和处理csv数据
import pandas as pd
# 用于处理日期,时间戳等数据
import time, datetime
# 用于生成直方图等图表
import matplotlib.pyplot as plt
# 用于对聊天内容进行分词处理
import jieba
# 用于生成词云图
from wordcloud import WordCloud,STOPWORDS,ImageColorGenerator
# 用于统计数组中元素出现次数
from collections import Counter
# 用于正则表达式提取数据
import re然后读取 message.csv 文件。
# 需要读取的数据列
cols = ["type", "status", "createTime", "content", "imgPath", "talkerId"]
# message.csv 文件所在路径
filename = "src/message.csv"
# 女朋友的talkerId
TalkerID = 162
# 读取文件
data = pd.read_csv(filename, usecols=cols)1.1 聊天消息概况统计
表中 type 列的值与消息类型对应情况,如下:
| type | 对应的消息类型 |
|---|---|
| 1 | 文字 |
| 2 | 图片 |
| 3 | 定位 |
| 34 | 语音 |
| 43 | 视频 |
| 47 | 表情包 |
| 49 | 分享链接 |
| 10000 | 撤回消息 |
| 822083633 | 引用回复 |
| 922746929 | 拍一拍 |
| 419430449 | 转账红包 |
| 486539313 | 公众号分享 |
| 754974769 | 视频号分享 |
| 1040187441 | 音乐分享 |
| 1090519089 | 传文件 |
注:以上是我通过比对微信聊天记录,大概推测所得,仅供参考,不一定对。
通过以下代码,可以统计得到聊天消息概况。
# 聊天消息总数
chatNum = 0
# 自己发送的消息
sendNum = 0
# 女朋友发送的消息
recvNum = 0
# 自己发送的消息总字数
hhMsgLen = 0
# 女朋友发送的消息总字数
yyMsgLen = 0
# 自己发送的最长消息的字数
hhMaxLen = 0
# 女朋友发送的最长消息的字数
yyMaxLen = 0
# 自己发送的长消息数(字数大于50)
hhLongMsg = 0
# 女朋友发送的长消息数(字数大于50)
yyLongMsg = 0
# 文字消息数
textNum = 0
# 图片消息数
imageNum = 0
# 语音消息数
audioNum = 0
# 视频消息数
videoNum = 0
# 表情包数
emojiNum = 0
# 其他未分类消息
other = 0
# 分享消息数
shareNum = 0
# 发送文件数
fileNum = 0
# 引用回复数
replyNum = 0
# 转账红包数
moneyNum = 0
# 定位消息数
locaNum = 0
# 拍一拍数
pypNum = 0
# 撤回消息数
retrNum = 0
# 统计消息条数
for index, msgType, status, createTime, content, imgPath, talkerId in data.itertuples():
# 限定聊天对象是女朋友
if talkerId == TalkerID:
chatNum += 1
if status == 2:
sendNum += 1
elif status == 4:
recvNum +=1
if msgType == 1:
textNum += 1
if status == 2:
hhMsgLen += len(content)
hhMaxLen = max(hhMaxLen, len(content))
if len(content) >= 50:
hhLongMsg += 1
elif status == 4:
yyMsgLen += len(content)
yyMaxLen = max(yyMaxLen, len(content))
if len(content) >= 50:
yyLongMsg += 1
elif msgType == 3:
imageNum += 1
elif msgType == 34:
audioNum += 1
elif msgType == 43:
videoNum += 1
elif msgType == 47:
emojiNum += 1
# 链接分享,公众号分享,视频号分享,音乐分享等统一计入分享消息数
elif msgType == 49 or msgType == 486539313 or msgType == 754974769 or msgType == 1040187441:
shareNum += 1
elif msgType == 822083633:
replyNum += 1
elif msgType == 1090519089:
fileNum += 1
elif msgType == 419430449 or msgType == 436207665:
moneyNum += 1
elif msgType == 10000:
retrNum += 1
elif msgType == 922746929:
pypNum += 1
elif msgType == 48 or msgType == -1879048186:
locaNum += 1
else:
other += 1
# 打印统计结果
print("聊天记录概况统计\n")
print("消息总条数:", chatNum)
print("---"*10)
print("鹤鹤发的消息数:", sendNum)
print("颖颖发的消息数:", recvNum)
print("鹤鹤发送的总字数:", hhMsgLen)
print("颖颖发送的总字数:", yyMsgLen)
print("鹤鹤发送的长消息数:", hhLongMsg, ",最长消息", hhMaxLen, "字")
print("颖颖发送的长消息数:", yyLongMsg, ",最长消息", yyMaxLen, "字")
print("---"*10)
print("文字:", textNum)
print("表情包:", emojiNum)
print("图片:", imageNum)
print("语音:", audioNum)
print("视频:", videoNum)
print("---"*10)
print("链接分享:", shareNum)
print("引用回复:", replyNum)
print("发送文件:", fileNum)
print("红包转账:", moneyNum)
print("撤回消息:", retrNum)
print("拍一拍:", pypNum)
print("发送定位:", locaNum)
print("---"*10)
print("未分类:", other)运行结果 :
聊天记录概况统计
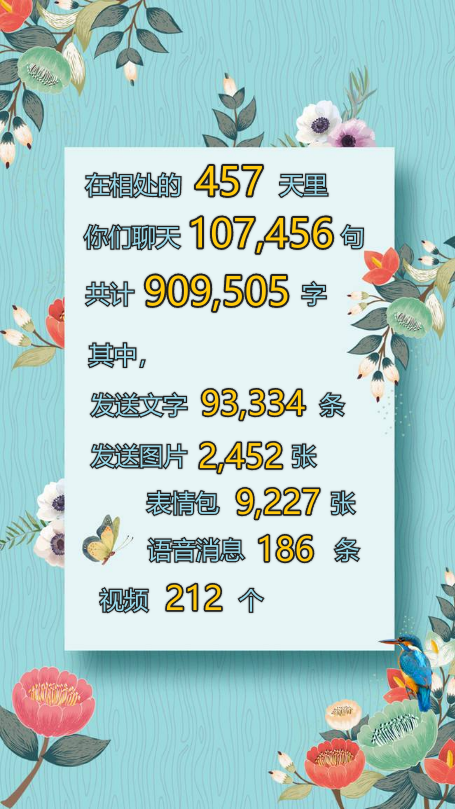
消息总条数: 107456
------------------------------
鹤鹤发的消息数: 51753
颖颖发的消息数: 55692
鹤鹤发送的总字数: 459031
颖颖发送的总字数: 450474
鹤鹤发送的长消息数: 220 ,最长消息 459 字
颖颖发送的长消息数: 64 ,最长消息 254 字
------------------------------
文字: 93334
表情包: 9227
图片: 2452
语音: 186
视频: 212
------------------------------
链接分享: 102
引用回复: 1541
发送文件: 20
红包转账: 30
撤回消息: 227
拍一拍: 102
发送定位: 9
------------------------------
未分类: 141.2 聊天时间段分析
根据数据表中的 createTime 字段,可以获取到消息发送的时间,进而可以进行聊天时间段分析。
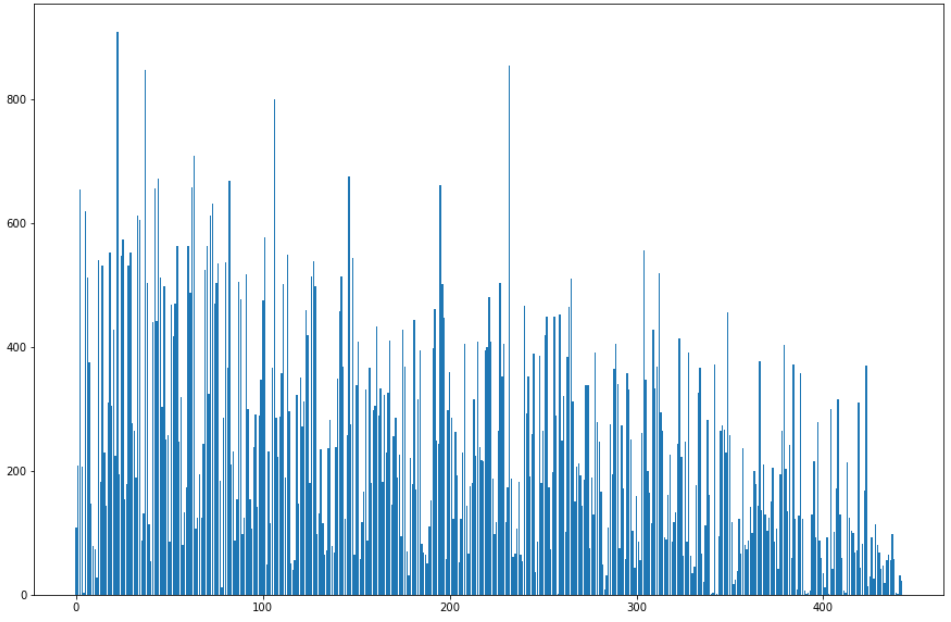
1.2.1 每天聊天消息数
# 定义字典,键为日期,值为该天聊天消息数
dayMsgDict = {}
# 统计每天的聊天消息数
for index, msgType, status, createTime, content, imgPath, talkerId in data.itertuples():
if talkerId == TalkerID:
timeArray = time.localtime(createTime/1000)
date = time.strftime('%Y-%m-%d', timeArray)
if dayMsgDict.get(date):
dayMsgDict[date] += 1
else:
dayMsgDict.setdefault(date, 1)
# 绘制直方图可视化展示
plt.figure(figsize=(15, 10))
plt.bar(range(len(dayMsgDict.keys())), dayMsgDict.values())
plt.show()运行结果:
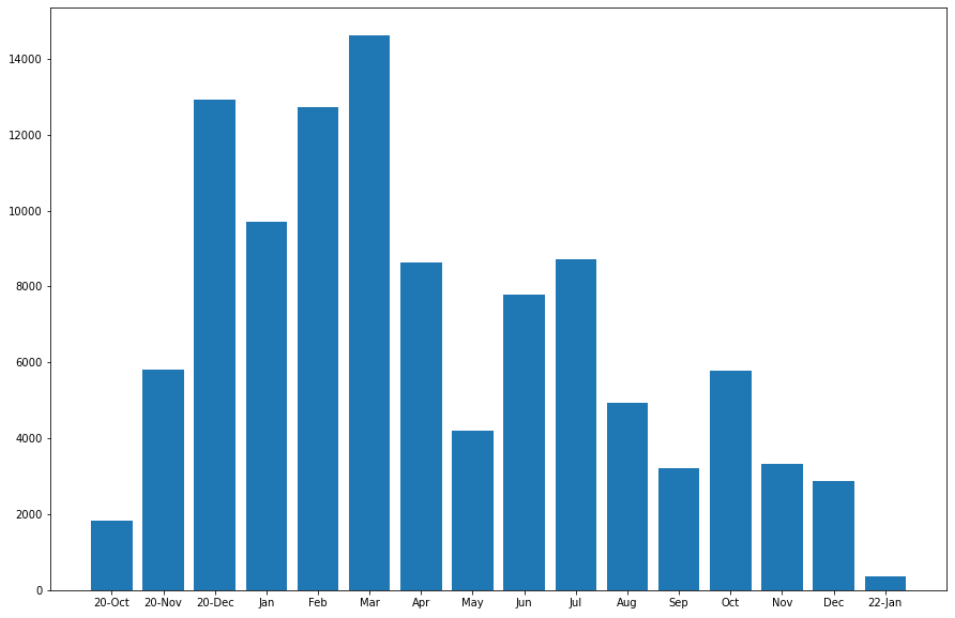
1.2.2 每月的聊天消息数
# 定义数组,从2020年10月起,至2022年1月,共 16 个月
monMsgArray = [0] * 16
# 统计每月的聊天消息数
for index, msgType, status, createTime, content, imgPath, talkerId in data.itertuples():
if talkerId == TalkerID:
timeArray = time.localtime(createTime/1000)
if timeArray.tm_year == 2020:
monMsgArray[timeArray.tm_mon - 10] += 1
elif timeArray.tm_year == 2021:
monMsgArray[timeArray.tm_mon + 2] += 1
if timeArray.tm_year == 2022:
monMsgArray[-1] += 1
# 绘制直方图可视化展示
plt.figure(figsize=(15, 10))
month_Label = ["20-Oct", "20-Nov", "20-Dec", "Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", "Dec", "22-Jan"]
plt.bar(range(len(monMsgArray)), monMsgArray, tick_label=month_Label)
plt.show()运行结果:
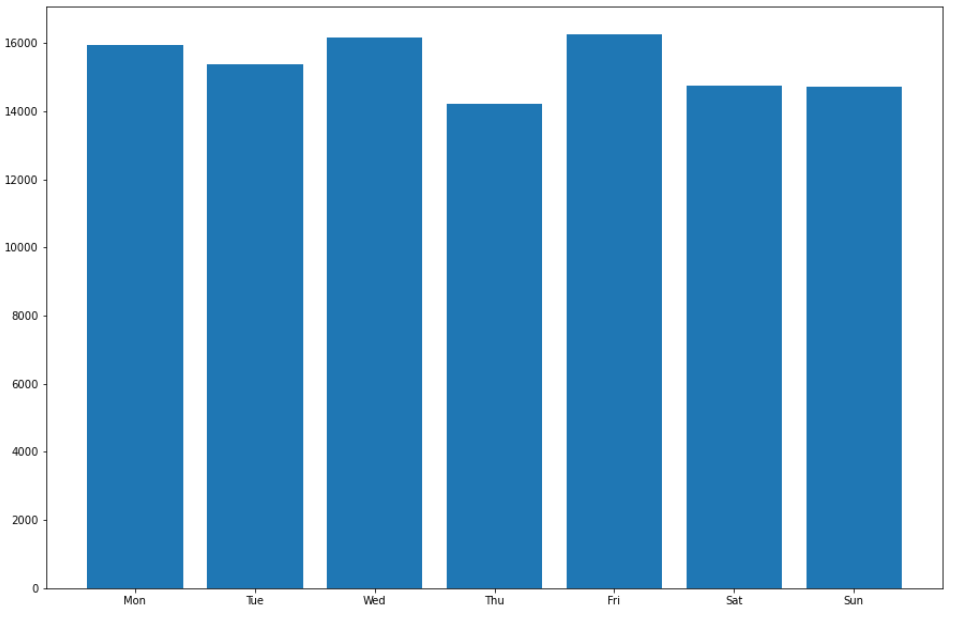
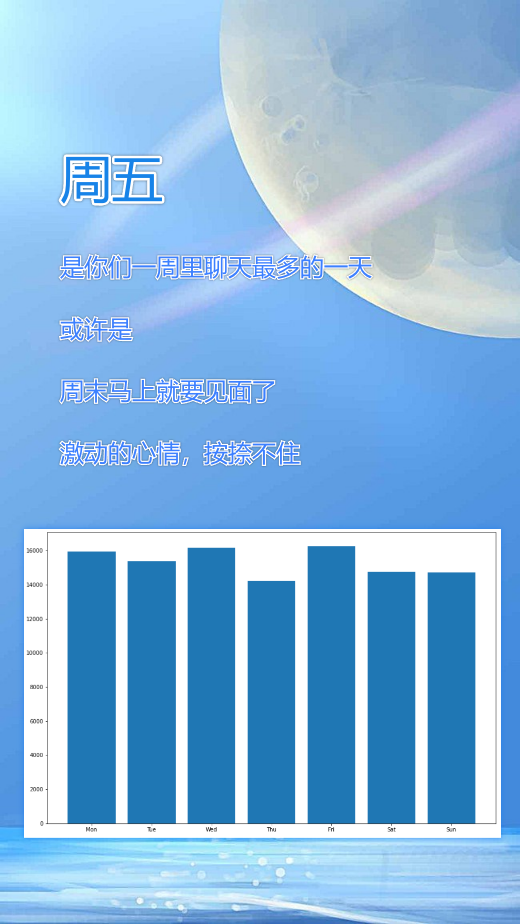
1.2.3 一周的聊天消息数
# 定义数组,从周一到周日,每天的聊天消息数
weekMsgArray = [0] * 7
# 统计从周一到周日,每天的聊天消息数
for index, msgType, status, createTime, content, imgPath, talkerId in data.itertuples():
if talkerId == TalkerID:
weekday = datetime.datetime.fromtimestamp(createTime/1000).weekday()
weekMsgArray[weekday] += 1
# 绘制直方图可视化展示
plt.figure(figsize=(15, 10))
weekday_Label = ["Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun"]
plt.bar(range(len(weekMsgArray)), weekMsgArray, tick_label=weekday_Label)
plt.show()运行结果:
1.2.4 一天的聊天消息数
# 定义数组,一天24小时
hourMsgArray = [0] * 24
# 统计一天24小时的聊天消息数
for index, msgType, status, createTime, content, imgPath, talkerId in data.itertuples():
if talkerId == TalkerID:
timeArray = time.localtime(createTime/1000)
hourMsgArray[timeArray.tm_hour] += 1
# 绘制直方图可视化展示
plt.figure(figsize=(15, 10))
hour_Label = [str(i) for i in range(0, 24)]
plt.bar(range(len(hourMsgArray)), hourMsgArray, tick_label=hour_Label)
plt.show()运行结果:
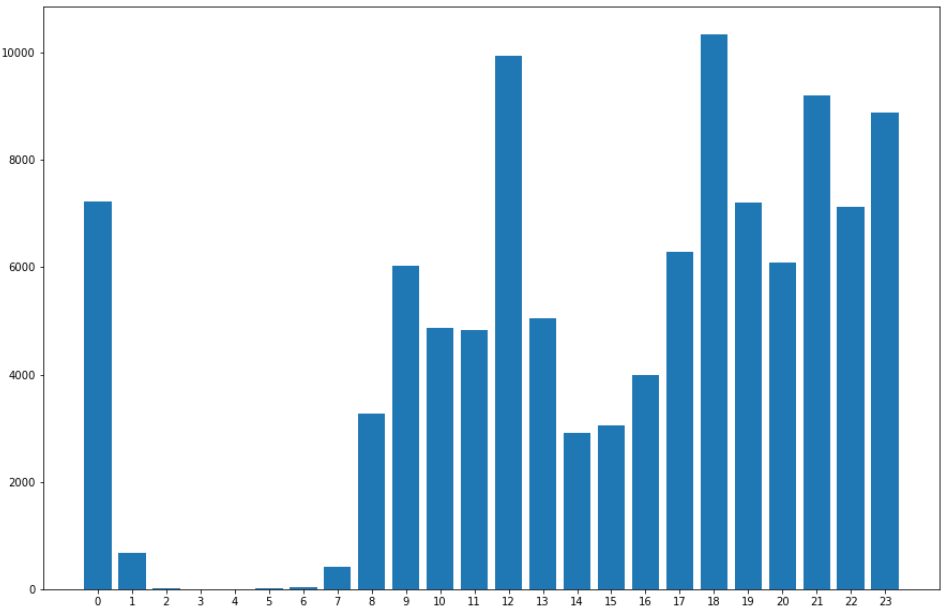
1.2.5 一些特别的日子
聊天最多的一天
# 聊天最多的一天,以及这天的聊天消息数
maxDay = 0
maxVal = 0
for key in dayMsgDict:
if maxVal < dayMsgDict[key]:
maxDay = key
maxVal = dayMsgDict[key]
# 打印统计结果
print(maxDay, "这一天,你们无话不谈,聊了", maxVal, "句")运行结果:
2021-03-28 这一天,你们无话不谈,聊了 909 句聊天最晚的一天
这里我以凌晨 5 点作为分界点,5 点之前属于晚睡,5 点之后属于早起。
# 聊天最晚的一天
latestDay = None
# 统计聊天最晚的一天
for index, msgType, status, createTime, content, imgPath, talkerId in data.itertuples():
if talkerId == TalkerID:
timeArray = time.localtime(createTime/1000)
if timeArray.tm_hour < 5:
if latestDay == None:
latestDay = timeArray
continue
ts1 = timeArray.tm_hour * 3600 + timeArray.tm_min * 60 + timeArray.tm_sec
ts2 = latestDay.tm_hour * 3600 + latestDay.tm_min * 60 + latestDay.tm_sec
if ts1 > ts2:
latestDay = timeArray
#打印统计结果
Date = time.strftime('%Y-%m-%d', latestDay)
Time = time.strftime('%H点%M分', latestDay)
print(Date, "这一天,你们睡得很晚,凌晨",Time, "仍在聊天")运行结果:
2021-05-30 这一天,你们睡得很晚,凌晨 04点40分 仍在聊天起床最早的一天
# 聊天最早的一天
earliestDay = None
# 统计聊天最早的一天
for index, msgType, status, createTime, content, imgPath, talkerId in data.itertuples():
if talkerId == TalkerID:
timeArray = time.localtime(createTime/1000)
if timeArray.tm_hour >= 5:
if earliestDay == None:
earliestDay = timeArray
continue
ts1 = timeArray.tm_hour * 3600 + timeArray.tm_min * 60 + timeArray.tm_sec
ts2 = earliestDay.tm_hour * 3600 + earliestDay.tm_min * 60 + earliestDay.tm_sec
if ts1 < ts2:
earliestDay = timeArray
#打印统计结果
Date = time.strftime('%Y-%m-%d', earliestDay)
Time = time.strftime('%H点%M分', earliestDay)
print(Date, "这一天,你们醒得很早,早上",Time, "便已开启新的一天")运行结果:
2021-07-11 这一天,你们醒得很早,早上 05点26分 便已开启新的一天1.3 聊天内容分析
1.3.1 最常说的词语
# 文字消息字符串
msgContent = ""
# 开始统计
for index, msgType, status, createTime, content, imgPath, talkerId in data.itertuples():
if talkerId == TalkerID and msgType == 1:
msgContent += content
# 剔除 Emoji 表情
pattern = re.compile(r"\[.+?\]")
msgContent = pattern.sub(r"", msgContent)
# jieba 分词
msg_all_split = jieba.cut(str(msgContent), cut_all=False)
# 剔除单字
all_ls = [word for word in msg_all_split if len(word)>1]
all_words = ' '.join(all_ls)
# 设置停用词
stopwords = STOPWORDS.copy()
stopwords.add('这个')
stopwords.add('就是')
stopwords.add('什么')
stopwords.add('然后')
stopwords.add('可以')
stopwords.add('没有')
stopwords.add('一个')
stopwords.add('不是')
stopwords.add('感觉')
stopwords.add('时候')
stopwords.add('觉得')
# 生成词云图
wc = WordCloud(width=1960, height=1080, background_color='white', font_path='STKAITI.TTF', stopwords=stopwords, max_font_size=400, random_state=50, collocations=False)
wc.generate_from_text(all_words)
# 词云图显示
plt.figure(figsize=(15, 10))
plt.imshow(wc)
plt.axis('off')
plt.show()运行结果:

我最常说的词语
# 我发送的文字消息
hhMsgContent = ""
# 开始统计
for index, msgType, status, createTime, content, imgPath, talkerId in data.itertuples():
if talkerId == TalkerID and msgType == 1:
if status == 2:
hhMsgContent += content
# 剔除 Emoji 表情
pattern = re.compile(r"\[.+?\]")
msgContent = pattern.sub(r"", hhMsgContent)
# jieba 分词
msg_all_split = jieba.cut(str(msgContent), cut_all=False)
# 剔除单字
all_ls = [word for word in msg_all_split if len(word)>1]
all_words = ' '.join(all_ls)
# 设置停用词
stopwords = STOPWORDS.copy()
# 生成词云图
wc = WordCloud(width=1960, height=1080, background_color='white', font_path='STKAITI.TTF', stopwords=stopwords, max_font_size=400, random_state=50, collocations=False)
wc.generate_from_text(all_words)
# 词云图显示
plt.figure(figsize=(15, 10))
plt.imshow(wc)
plt.axis('off')
plt.show()运行结果:

女朋友最常说的词语
# 女朋友发送的文字消息
yyMsgContent = ""
# 开始统计
for index, msgType, status, createTime, content, imgPath, talkerId in data.itertuples():
if talkerId == TalkerID and msgType == 1:
if status == 4:
yyMsgContent += content
# 剔除 Emoji 表情
pattern = re.compile(r"\[.+?\]")
msgContent = pattern.sub(r"", yyMsgContent)
# jieba 分词
msg_all_split = jieba.cut(str(msgContent), cut_all=False)
# 剔除单字
all_ls = [word for word in msg_all_split if len(word)>1]
all_words = ' '.join(all_ls)
# 设置停用词
stopwords = STOPWORDS.copy()
# 生成词云图
wc = WordCloud(width=1960, height=1080, background_color='white', font_path='STKAITI.TTF', stopwords=stopwords, max_font_size=400, random_state=50, collocations=False)
wc.generate_from_text(all_words)
# 词云图显示
plt.figure(figsize=(15, 10))
plt.imshow(wc)
plt.axis('off')
plt.show()运行结果:

1.3.2 最常用的Emoji表情
# 正则表达式,提取聊天文字中的emoji表情
pattern = re.compile(r"\[.+?\]")
# hhMsgContent 为前面统计好的我发的文字消息
hhEmoji = re.findall(pattern, hhMsgContent)
# yyMsgContent 为前面统计好的女朋友发的文字消息
yyEmoji = re.findall(pattern, yyMsgContent)
# 按照出现次数统计
hh = Counter(hhEmoji)
yy = Counter(yyEmoji)
# 打印统计结果
print("鹤鹤发的表情数:", len(hhEmoji))
print("颖颖发的表情数:", len(yyEmoji))
print("---"*10)
print ("鹤鹤最常用的 10 个表情:\n", hh.most_common(10))
print("---"*10)
print ("颖颖最常用的 10 个表情:\n", yy.most_common(10))运行结果:
鹤鹤发的表情数: 15768
颖颖发的表情数: 21531
------------------------------
鹤鹤最常用的 10 个表情:
[('[破涕为笑]', 5083), ('[捂脸]', 4792), ('[偷笑]', 1829), ('[让我看看]', 1361), ('[奸笑]', 373), ('[发呆]', 318), ('[嘿哈]', 268), ('[皱眉]', 223), ('[苦涩]', 208), ('[憨笑]', 122)]
------------------------------
颖颖最常用的 10 个表情:
[('[破涕为笑]', 9462), ('[让我看看]', 5413), ('[捂脸]', 2459), ('[苦涩]', 2062), ('[旺柴]', 944), ('[偷笑]', 231), ('[白眼]', 154), ('[发呆]', 64), ('[奸笑]', 60), ('[666]', 55)]这样看可能看不出来,复制到微信里,就会显示对应的表情了。

1.3.3 最常发的表情包图片
# 我发送的表情包列表
hhImgList = []
# 女朋友发送的表情包列表
yyImgList = []
# 统计数据
for index, msgType, status, createTime, content, imgPath, talkerId in data.itertuples():
if talkerId == TalkerID and msgType == 47:
if status == 2:
hhImgList.append(imgPath)
elif status == 4:
yyImgList.append(imgPath)
# 统计每个表情包出现次数
hhImg = Counter(hhImgList)
yyImg = Counter(yyImgList)
# 打印统计结果
print("鹤鹤共发送了", len(hhImgList), "个表情包")
print("颖颖共发送了", len(yyImgList), "个表情包")
print("---"*10)
print ("鹤鹤表情包前十名:\n", hhImg.most_common(10))
print("---"*10)
print ("颖颖表情包前十名:\n",yyImg.most_common(10))运行结果:
鹤鹤共发送了 4203 个表情包
颖颖共发送了 5024 个表情包
------------------------------
鹤鹤表情包前十名:
[('6b5a13890545c9675e6029fbee395560', 319), ('d9f537281429695f9c299049814e3e33', 164), ('8fb0ddeea33701832c86167a141452df', 114), ('25b8abcd5318ded9ade61a6ec1287a95', 91), ('7f69ba3a4ed01d1c16c3b6576c45d24e', 90), ('4ce13465607eb3243d6e80e7a95b838f', 81), ('a9d5dbb4c0fba9a1af0ec2e6e064977b', 80), ('ce58baf1002411bdafd299a689cadfe4', 76), ('c1ed2b89e38cfded0461bc95db1ab522', 75), ('d16c0b43b9ee901d92f9542b1033234a', 70)]
------------------------------
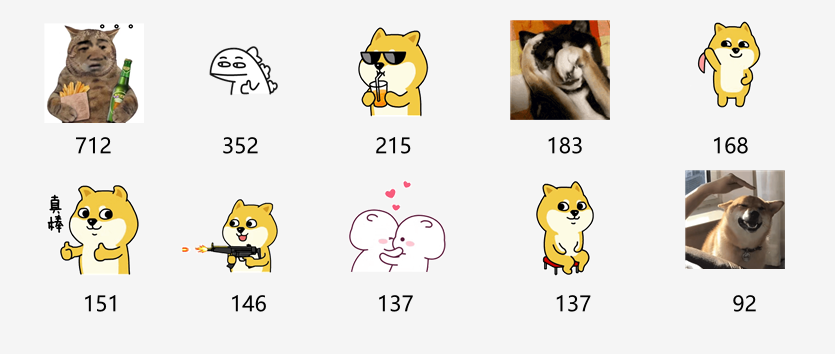
颖颖表情包前十名:
[('a9d5dbb4c0fba9a1af0ec2e6e064977b', 712), ('477e31cf6e2a747c96e1248a02605756', 352), ('e976c1e3f56a32db3c2f49de72daa616', 215), ('4d21237942192184a4c8a57ab34fb2fa', 183), ('125d7792a060cece7edef87d71b40837', 168), ('4ce13465607eb3243d6e80e7a95b838f', 151), ('7c04a4df048874f088dc8832c45e3fb6', 146), ('b2f427b22d1e581923837acd7165e882', 137), ('6b5a13890545c9675e6029fbee395560', 137), ('b83d0a5929cdf92aeb05eefaf3612bea', 92)]注:统计得到的
imgPath值为表情包图片的 MD5 值,对应的表情包可以通过发送时间createTime,在微信聊天记录中对照着找到。
2. 年度报告







鹤鹤年度表情包前十名

颖颖年度表情包前十名
我是机灵鹤,一个代码写的不错,还有点小浪漫的程序员。

