大家好,我是机灵鹤。
前段时间完成了一个爬虫项目,完成了国内 13 个主流新闻网站的内容采集(根据关键词爬取)。包括
中国日报网,中国新闻网,人民网,光明网,国际在线,央广网,央视网,中国网,凤凰网,网易新闻,新浪新闻,中国青年网,中青在线
虽然 新闻网站 这种文字类的爬虫相对较为简单,但是爬取过程中仍然遇到了不少的坑,项目完成后也有不小的收获。
现将自己的心得整理记录分享,希望对大家能有所帮助。
0. 目录
- 正文内容页面格式不统一
- 网页编码自动识别
- 获取总页数的几种常用方法
- 如何实现断点续存
- 文件名特殊字符剔除
- 网页中图片和视频的提取方法
- 使用多线程提高爬取效率
- 异常处理增加爬虫稳健性
- 大文件的分批读取
- 参数可以放到配置文件里
1. 正文内容页面格式不统一
大家可能遇到过这种情况,在根据关键词搜索结果爬取新闻时,新闻正文页格式不统一。
这些新闻的网页或者来自不同站点,或者来自不同新闻板块,或者此前经历过网站改版,种种因素导致网页页面格式不一致,使得爬虫无法使用统一的解析函数来解析,给我们的爬取工作来带很大的麻烦。
比如在《人民网》,以 春节 为关键词的搜索结果中,就有多种不同格式的新闻页:
《李焕之与《春节序曲》》中,正文内容在属性为 rm_txt_con 的 div 标签下。

在《平台春节“发红包”如何实现双赢》中,正文内容在属性为 artDet 的 div 标签下。

而《春节档电影市场再创佳绩》中,正文内容在属性为 show_text 的 div 标签下。

解析网页时必须对各种界面进行兼容适配,否则轻则漏爬一批新闻网页,重则触发异常甚至导致程序崩溃。
针对上述情况,如果大家有比较好的解决方法的话,欢迎找我交流。
我简单讲讲我的解决方法。
首先我们可以使用最简单的方法 if...else... 来判断,示例代码如下:
cont1 = bsObj.find("div", attrs={"class": "rm_txt_con"})
if cont1:
# parse content 1
else:
cont2 = bsObj.find("div", attrs={"class": "artDet"})
if cont2:
# parse content 2
else:
cont3 = bsObj.find("div", attrs={"class": "show_text"})
if cont3:
# parse content 3
else:
print("parse failed")就是先获取一个标签,如果获取到了就按照对应规则解析正文,如果没获取到就继续找下一个......直到所有已知的标签全部检索完毕,若还没有获取到,则输出获取失败。
这种方法逻辑简单,实现起来也很方便,也确实可以解决问题。
但是在页面格式类型较多时,代码就会显得非常臃肿,尤其是 python 代码需要严格执行缩进的情况下,代码会变得特别不美观,维护起来也非常不方便。
所以我们可以用走配置的方法,对上述代码进行优化。
# 走配置的方法
confilter = [
{"tag": "div", "type": "class", "value": "rm_txt_con"},
{"tag": "div", "type": "class", "value": "box_con"},
{"tag": "div", "type": "class", "value": "box_text"},
{"tag": "div", "type": "class", "value": "show_text"},
{"tag": "div", "type": "id", "value": "p_content"},
{"tag": "div", "type": "class", "value": "artDet"},
]
for f in confilter:
con = bsObj.find(f["tag"], attrs={f["type"]: f["value"]})
if con:
# parse content
break这样的话,每增加一种网页类型,只需要在配置中增加一行既可,非常方便。
2. 网页编码自动识别
不同网页使用的字符编码各不相同,最常用的是 utf-8 和 GB2312 。
如果解析网页内容时,字符编码设置不匹配,就会导致爬取到的文字乱码。
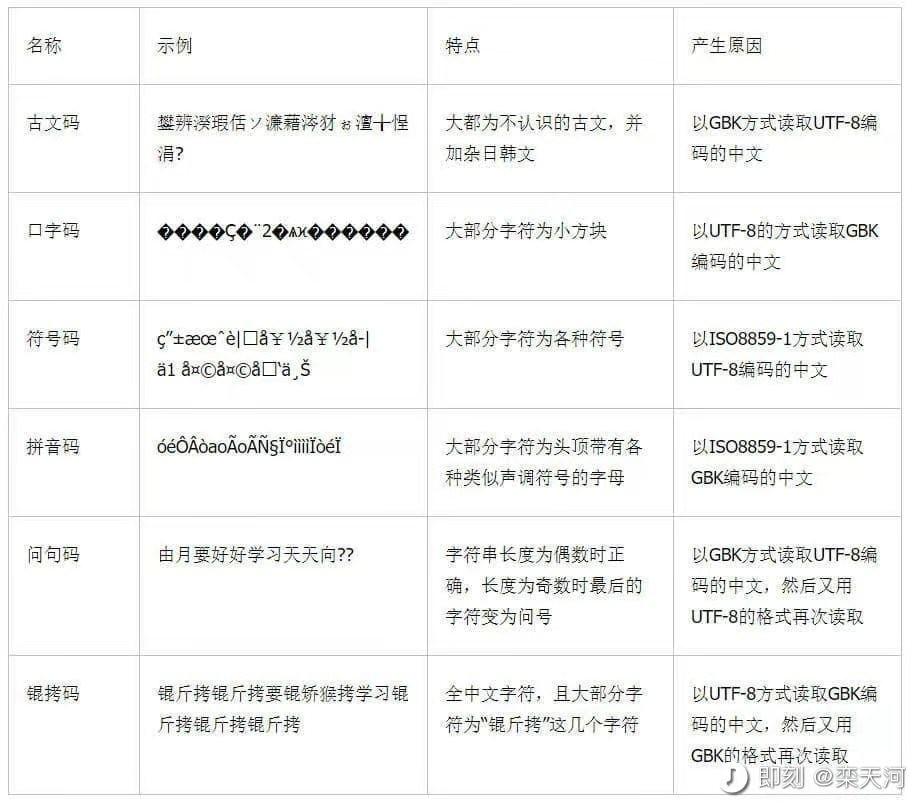
如何自动识别网页的编码,可以试一下 chardet 库,它可以根据网页内容自动推测最有可能的编码格式,以及相应的置信度。
import chardet
import requests
r = requests.get("https://www.xxxxxxxxx.com")
# 推测网页内容的编码格式
data =chardet.detect(r.content)
# 结果是 json 格式,
# data["encoding"] 为编码格式,data["confidence"] 为置信度
if data["confidence"] > 0.9:
r.encoding = data["encoding"]
else:
r.encoding = "utf-8"
print(r.text)当然,也有更加简洁的方法 apparent_encoding 。
import chardet
import requests
r = requests.get("https://www.xxxxxxxxx.com")
r.encoding = r.apparent_encoding
print(r.text)两者识别效果差不多,后者写法更加简洁,使用更加方便;前者可以查看更加详细的编码识别信息。具体使用哪一种方法,就要实际情况自行选择了。
不过,在使用过程中发现,这两种识别网页编码的方法并非百分百准确识别,有些新闻网页(我猜测网页中混合使用了多种编码格式的内容)会识别为错误的编码,导致解析出乱码。
这个情况我也没有想到合适的解决方法,目前我的解决方法是,如果编码识别结果的置信度低于 90%,则视为识别失败,此时根据具体情况给它一个默认的编码格式,如 utf-8 或者 GB2312 了。
3. 获取总页数的几种常用方法
当我们循环爬取新闻列表时,会遇到一个非常重要的问题,就是程序到底需要循环多少次。
翻译过来就是 新闻列表共有多少页 。
以关键词搜索的搜索结果,不同的网站有不同的展示方式,对应着获取总页数的方式也各不相同。
3.1 返回结果 json 里包含总页数
有的网站使用的是 Ajax 动态加载数据,也就是说服务器会把每一页的新闻数据以 json 的形式发送过来。而一般情况下,在这条请求中会包含了数据 总条数 和 总页数 的信息。
以 凤凰网 为例,在关键词搜索结果的请求响应消息中,包含了 total 和 totalPage 两个字段,分别代表搜索结果的总条数和总页数。

这种情况下,我们直接解析 json 提取总页数即可。
示例代码如下:
page = jsonObj["data"]["totalPage"]
print(int(page))当然为了防止将来消息协议变化,解析 json 时找不到键而报错崩溃,可以在解析前加一道判断(判断键是否存在),增加程序的稳健性。
if "data" in jsonObj and "totalPage" in jsonObj["data"]:
page = jsonObj["data"]["totalPage"]
print(int(page))3.2 解析 尾页 按钮的链接
在有翻页按钮的网站,如果有 尾页,末页,或 最后一页 等按钮,解析该按钮的跳转链接,可以知道搜索结果的总页数。
以 中国新闻网 为例,查看 尾页 按钮的点击事件时,会发现它点击时会调用一个 ongetKey() 的 JavaScript 方法,经过观察测试后发现,其中传入的参数 98 便是点击后跳转的页码。

所以,我们只需要获取到 尾页 按钮的点击响应事件,提取出它的参数,便得到了总页数。
示例代码如下:
# 获取尾页按钮
bsObj = BeautifulSoup(html, "html.parser")
pagediv = bsObj.find("div", attrs={"id": "pagediv"})
lastPage = pagediv.find_all("a")[-1]
# 从尾页按钮的 href 中提取总页码
total = re.findall(r"\d+", lastPage["href"])
print(int(total[0]))我们把代码完善一下,增加其稳健性,并进行一下封装。
def getTotal_ZGXWW(html):
bsObj = BeautifulSoup(html, "html.parser")
pagediv = bsObj.find("div", attrs={"id": "pagediv"})
if not pagediv:
return 0
lastPage = pagediv.find_all("a")
if len(lastPage) > 0 and lastPage[-1] and "href" in lastPage[-1]:
total = re.findall(r"\d+", lastPage[-1]["href"])
if len(total) > 0:
return int(total[0])
return 03.3 搜索结果总数除以每页展示数
搜索结果页面,一般会显示本次搜索总条目数,使用总数除以每页的条目数,结果取整,即可得到总页数。
以 央视网 为例,在页面顶部的 <div class = "lmdhd"> 标签中,有显示本次搜索结果的总条数。

而一般每一页显示的条目数量固定,我们只需要用总条数除以每页条目数,结果向上取整,即可得到总页数。
示例代码如下:
bsObj = BeautifulSoup(html, "html.parser")
# 获取标签
lmdhd = bsObj.find("div", attrs={"class": "lmdhd"})
# 正则提取总条数
total = re.findall(r"\d+", lmdhd.text)
# 计算总页数(每页 10 条)
totalPage = Math.ceil(int(total[0]) / 10)
print(totalPage)我们把代码完善一下,增加其稳健性,并进行一下封装。
def getTotal_YSW(html):
bsObj = BeautifulSoup(html, "html.parser")
lmdhd = bsObj.find("div", attrs={"class": "lmdhd"})
if not lmdhd:
return 0
total = re.findall(r"\d+", lmdhd.text)
if len(total) > 0:
totalPage = Math.ceil(int(total[0]) / 10)
return totalPage
return 0不过这种方法不一定准确,因为很多网站的搜索结果并不是全量展示的,仅仅展示前若干页的数据。
这样就会导致一些问题,如爬取到大量重复数据;在爬取过程中出现空数据甚至报错等,所以需要做好 数据去重 和 异常捕获 等工作。
3.4 循环爬取直到终止条件
对于一些瀑布流展示数据的网站,对页码的划分不是很明显,我们没有办法直接得知它的总页数是多少。
这样的话,我们可以在 while(True) 循环中加入终止条件的判断,如 返回的数据为空,发布时间不符合要求 等条件。
示例代码(伪代码)如下:
- 每次循环获取下一页链接,下一页链接为空时退出
while(True):
# 爬取数据,以及下一页的链接
data, url = getData_And_NextUrl(url)
# 保存数据
saveData(data)
# 当下一页链接为空时退出
if not url:
break;- 每次循环获取数据,数据为空时退出
while(True):
# 爬取数据,以及下一页的链接
data, url = getData_And_NextUrl(url)
# 当数据为空时退出
if not data:
break;
# 保存数据
saveData(data)4. 如何实现断点续存
爬虫不可避免会出现报错崩溃退出的情况,对于一个爬取数据量比较大的爬虫来讲,如果每次崩溃都需要从头重新开始爬取,无疑是很浪费时间,和令人崩溃的。
所以加入 断点续存 的功能就显得很人性化了。
访问新闻详情页之前,先检索本地有没有对应的已保存好的新闻文件,若有,则跳过,若没有,则开始爬取。
示例代码如下:
# fetchNewsUrlList 函数用来获取搜索结果中某一页的全部新闻链接
# keyword 是搜索的关键词,page 是页码
newsList = fetchNewsUrlList(keyword, page)
for url in newsList:
# getFilenameByUrl 函数用来根据 url 获取保存该网页新闻的文件名
filename = getFilenameByUrl(url)
# path 是文件保存的路径
# 如果该文件存在,则跳过
if os.path.exists(path + filename):
continue
# 若没有该文件,则爬取该网页并保存新闻内容
content = getNewsContent(url)
saveData(content)通过这种机制,我们可以快速跳过之前爬取完成的数据,直接从上次断掉的地方接着爬取,不仅可以节省大量的时间和网络资源,也一定程度上降低了对目标网站造成的负荷。
此外,对于一些需要定期增量爬取数据的项目中,这种 断点续存 机制也是很有必要的。
5. 文件名中特殊字符剔除
我们知道 .txt 文件的文件名中,是不允许包含一些特殊字符的。
文件名不能包含下列任何字符:
\/:*?"<>|

如果我们使用新闻标题作为保存的文件名,标题中的一些特殊字符很可能会导致文件保存失败,甚至报错造成出现崩溃。
所以,如果我们使用新闻标题作为保存的文件名,需要对文件名进行一些处理,剔除或替换其中的特殊字符。
# 使用正则表达式剔除特殊字符
import re
def fixFilename(filename):
intab = r'[?*/\\|.:><]'
newName = re.sub(intab, "", filename)
return newName
filename = "*/fadsa-*a/s-*|,.;<>-"
print(fixFilename(filename))运行结果:
fadsa-as-,;-使用处理后的字符串做文件名时,就不会有问题了。
不过有的同学可能会发现这样的情况,就是上面的代码把文件名中的特殊字符全部剔除掉了,这样虽然保存时不会报错了,但是文件名的样式也被搞乱了。
所以你可以用 替换字符 的方法来解决。
# 将特殊字符替换成对应的中文字符(或自定义字符)
def fixFilename(filename):
cfg = [
{"char":"?", "rep": "?"},
{"char":"*", "rep": ""},
{"char":"/", "rep": ""},
{"char":"\\", "rep": ""},
{"char":"|", "rep": ""},
{"char":".", "rep": "。"},
{"char":":", "rep": ":"},
{"char":">", "rep": "》"},
{"char":"<", "rep": "《"},
]
for item in cfg:
filename = filename.replace(item["char"], item["rep"])
return filename
filename = "*/fadsa-*a/s-*|,.;<>-"
print(fixFilename(filename))运行结果:
fadsa-as-,。;《》-6. 网页中图片和视频的提取方法
跟文字类似,有的网站的图片数据是以 json 格式返回的,有的则是渲染在 html 页面中返回的。
6.1 从 JSON 中提取数据
如果是 json 格式的数据,解析就非常简单了,按正常的 json 解析流程解析即可。
例如,我们构造一个 json 格式的示例数据:
data = {
"content": [
{
"id" : "item_ID_0001",
"img" : "https://www.asdasdasd.com/asdasdasd.jpg"
},
{
"id" : "item_ID_0002",
"img" : "https://www.asdasdasd.com/qweqweqwe.jpg"
},
]
}数据解析示例代码如下:
# 通过 ["content"] 可以获得 data 中 "content" 键对应的值
content = data["content"]
print(content)
# 运行结果:
# [{'id': 'item_ID_0001', 'img': 'https://www.asdasdasd.com/asdasdasd.jpg'},
# {'id': 'item_ID_0002', 'img': 'https://www.asdasdasd.com/qweqweqwe.jpg'}]
# content 是一个数组,有两个元素,我们用 for in 循环来遍历
for item in content:
print(item)
# 运行结果:
# {'id': 'item_ID_0001', 'img': 'https://www.asdasdasd.com/asdasdasd.jpg'}
# {'id': 'item_ID_0002', 'img': 'https://www.asdasdasd.com/qweqweqwe.jpg'}
# item 也可以用同样的方式解析,得到 "img" 键对应的值
for item in content:
img = item["img"]
print(img)
# 运行结果
# https://www.asdasdasd.com/asdasdasd.jpg
# https://www.asdasdasd.com/qweqweqwe.jpg这样便可以从 json 中解析得到我们想要的数据,包括图片链接,视频链接数据等。
6.2 从 HTML 中提取图片数据
但是大部分情况下,图片数据是渲染在 html 中的,需要解析网页源码才能得到。解析 html 的方式很多,下面我用 BeautifulSoup 为例进行讲解。
一般来说,显示图片的标签为 <img> ,属性名 src 为图片的链接。
from bs4 import BeautifulSoup
# html 为此前获取得到的网页源码
bsObj = BeautifulSoup(html, "html.parser")
# 获取网页中的全部 <img> 标签
imageList = bsObj.find_all("img")
# 遍历 <img> 标签,提取图片链接
for img in imageList:
# 通过 ["src"] 可以获取标签中的 "src" 属性
link = img["src"]
print(link)有的网站图片懒加载,src是一个统一的占位图片,甚至可能没有 src 属性,而真实的图片链接在自定义属性如 data-url 中,需要做好兼容处理。
from bs4 import BeautifulSoup
# html 为此前获取得到的网页源码
bsObj = BeautifulSoup(html, "html.parser")
imageList = bsObj.find_all("img")
for img in imageList:
link = img["data-url"]
print(link)对于获取到的图片链接,每个网站的显示格式也有细微差别。
# 有的图片是完整的链接,如:
imgUrl1 = "https://www.xxxxxx.com/asdasdasd.jpg"
# 有的图片缺少 http:(或 https:)
imgUrl2 = "//www.xxxxxx.com/asdasdasd.jpg"
# 有的图片是相对路径,需要补全域名
imgUrl3 = "./asdasdasd.jpg"对于不完整的图片链接,需要自己补全。
6.3 从 HTML 中提取视频地址
视频一般在 <video> 标签中,标签的属性名 src 为视频的链接。
一般来说,长视频网站的视频都是
m3u8格式,对应的video标签中的src是一个blob:开头的地址,这种解析起来稍稍复杂一些,本文暂且不谈。而短视频网站中的视频,一般不需要经过切片处理,对应的
video标签中的src是视频的地址,可以通过这个地址直接播放和下载视频。
我爬的这些新闻网站,大部分的视频都是 .mp4 格式的,直接提取链接即可。
from bs4 import BeautifulSoup
# html 为此前获取得到的网页源码
bsObj = BeautifulSoup(html, "html.parser")
# 获取网页中的所有 <video> 标签
videoList = bsObj.find_all("video")
# 遍历 <video> 标签,提取视频链接
for video in videoList:
videoUrl = video["src"]
print(videoUrl)不过类似于图片懒加载,很多网站中,<video> 标签中的 src 属性是动态赋值的,甚至整个 <video> 标签都是 js 动态创建出来的,这种情况下,直接从 HTML 源码中查找 <video> 标签提取视频链接的方式是行不通的。
经过观察发现,这种情况下的视频链接写在 <script> 标签下的 js 脚本中,为了方便,我们可以直接使用 正则表达式 用来提取。
import re
result = re.search('http.*mp4', html)
if result:
video = result.group()
print(video)这种方式会将所有开头是 http ,结尾是 mp4 的字符串提取出来,有可能会提取到重复的链接,也可能会提取到无关的视频链接,也有可能会提取到不完整的视频链接(如果后面带参数的话)。
需要根据实际情况调整自己的正则表达式和筛选策略。
7. 使用多线程提高爬取效率
在我前段时间完成的新闻网站爬虫项目中,需要爬取 13 个新闻网站,每个网站需要分别爬取数百个关键词的搜索结果,最终爬到的文件数量要近百万个,几十个GB 大小。
这么庞大的数据量,如果用单线程来跑,昼夜不停的跑估计得至少爬一个月吧。
所以使用多线程就非常有必要了,可以极大提高爬取效率(最后大概两三天时间便爬完了)。
7.1 初识多线程
假设我们有 spider_1() 、spider_2() 、spider_3() 三个函数。
def spider_1():
for i in range(10):
print("this is thead spider_1")
def spider_2():
for i in range(10):
print("this is thead spider_2")
def spider_3():
for i in range(10):
print("this is thead spider_3") 当使用单线程运行时,代码如下:
if __name__ == "__main__":
spider_1()
spider_2()
spider_3()三个函数依次执行,后者需要等前者完全执行完成后才会开始,总耗时为每个函数耗时之和。
如果希望提高执行效率,缩短程序耗时,那么可以改为使用 多线程 。
多线程可以用 threading 这个库。示例代码如下:
import threading
if __name__ == "__main__":
threading.Thread(target=spider_1).start()
threading.Thread(target=spider_2).start()
threading.Thread(target=spider_3).start()如上方式,便启动了 3 条线程,此时 spider_1() 、spider_2() 、spider_3() 三个函数同时并行运行,总耗时为 3 个函数中耗时最长的那个函数的耗时。
相比于依次执行,效率得到了极大提高。
7.2 带参数的函数
当然,如果多线程执行的函数有参数的话,可以通过 args 来传参,如:
threading.Thread(target=spider_1, args=(name,)).start()注意,args=(name,) 中最后一个参数后面的逗号 , 不要忘记。
示例代码如下:
import threading
def spider_1(name):
for i in range(10):
print("this is thead spider_1" + name)
def spider_2(name):
for i in range(10):
print("this is thead spider_2" + name)
def spider_3(name):
for i in range(10):
print("this is thead spider_3" + name)
if __name__ == "__main__":
name1 = "aaa"
name2 = "bbb"
name3 = "ccc"
threading.Thread(target=spider_1, args=(name1,)).start()
threading.Thread(target=spider_2, args=(name2,)).start()
threading.Thread(target=spider_3, args=(name3,)).start()7.3 线程锁
对于大部分操作来讲,每个线程可以同时进行,互不影响,比如说发起网络请求,解析数据等;但对于有些操作来说,线程之间是互斥的,比如说文件读写,数据库操作等,同一时间只能允许一条线程使用。
而多线程启动以后,各个线程执行的顺序、进度都是不确定的。如果不做特殊处理,必然会出现各个线程争夺资源的情况。
以文件读写为例,当一个线程打开文件写入数据,在它写入完成关闭文件之前,文件都会处于只读状态。如果此时另一个线程也来向文件里写数据,该线程就会报错,文件处于只读状态无法写入。
这时候我们就可以用 线程锁 来解决。
在如文件读写,数据库操作等操作环节上锁,每次只放一个线程进去,等操作结束后再解锁,这样避免多个线程 "打架" ,造成错误。
示例代码如下:
lock = threading.Lock()
def saveQuestionDB(id, title, url):
# 线程锁 上锁
lock.acquire()
# 数据库操作,每次只允许一条线程进行操作
try:
sql = "insert into questions values (%s,'%s','%s')"%(id, title, url)
cursor.execute(sql)
db.commit()
except Exception as e:
db.rollback()
print(e)
# 线程锁 解锁
lock.release()7.4 多线程任务分配
前面我们知道,程序运行的总时长,是根据耗时最长的那条线程来定的,所以为了尽可能缩短程序总耗时,我们需要把任务尽可能均匀地拆分给每一条线程。
以我的新闻爬虫项目为例,为了尽可能均匀地分配任务,同时使各线程的任务尽可能相对独立,于是我将每个网站每个关键词划分为一个线程,共 网站个数 * 关键词条数 条线程。
示例代码如下:
import threading
# 各个新闻网站的爬虫程序入口
def Spider_ZGRBW(keyword):
# 中国日报网
pass
def Spider_ZGXWW(keyword):
# 中国新闻网
pass
def Spider_RMW(keyword):
# 人民网
pass
# ......
# 多线程启动函数
def start_All_Spider(keyword):
threading.Thread(target=Spider_ZGRBW, args=(keyword,)).start()
threading.Thread(target=Spider_ZGXWW, args=(keyword,)).start()
threading.Thread(target=Spider_RMW, args=(keyword,)).start()
# ......
if __name__ == "__main__":
# keywordList 是关键词列表
for keyword in keywordList:
start_All_Spider(keyword)8. 异常处理增加爬虫稳健性
程序要想持久稳健地运行下去,代码写法要规范严谨,尽可能减少出错的可能;异常处理也必须要做好,不能因为报错而导致程序崩溃。此外有需要的话,还可以输出错误日志,方便后续调试。
8.1 代码写法要规范
下面是我总结的一些常见的容易出错的地方,大家写代码时候可以注意一下。
- 数组元素访问前要先判断数组大小,避免访问越界
titleList = bsObj.find_all("h1")
if len(titleList) >= 2:
# 访问前必须判断数组大小,避免数组越界访问
title = titleList[0].text
subTitle = titleList[1].text
print(title, subTitle)获取组件要考虑为空的情况,组件使用前要判空,避免直接操作空对象。
cntObj:
content = cntObj.text
print(content)- 访问标签属性前要先判断标签是否存在该属性,否则可能会报错
imgTag = bsObj.find("img");
# 通过 has_attr 判断标签是否包含属性
if imgTag and imgTag.has_attr("src"):
imgSrc = imgTag["src"]
print(imgSrc)- 解析
json时,判断是否有键,否则可能会报错
# 通过 in 判断 json 中是否包含该键值对
if "totalPages" in jsonObj:
page = jsonObj["totalPages"]
print(page)- 保存文件前,先判断路径是否存在,若不存在,需要先创建。
# 通过 os.path.exists 判断路径是否存在
if not os.path.exists(path):
# 通过 os.makedirs 创建路径
os.makedirs(path)8.2 异常捕获
规范的编码习惯可以帮我们避免很多的 Bug,但是保险起见,在一些容易出错的地方,如:网络请求,文件读写等位置,最好还是使用 try...catch... 进行异常捕获,增加程序稳健性。
示例代码如下:
import requests
url = "https://www.baidu.com"
try:
r = requests.get(url)
r.encoding = r.apparent_encoding
r.raise_for_status()
print(r.text)
except Exception as e:
print("Error:", e)8.3 输出日志
使用爬虫爬取数据时,经常会遇到有些网页爬取失败的情况。一般情况下,为了程序的稳健性,我们遇到网页爬取失败时可以直接跳过,先爬取其他网页。
但是造成网页爬取失败的原因是多样的,有可能是网页本身不可访问,有可能是触发反爬机制暂时被限制访问了,也可能是网页格式不一致没解析出来......
如果是由于网页本身不可访问,那我们可以直接忽略;但如果是爬虫不完善导致的爬取失败,我们则需要对这部分网页进行重新爬取。
所以,为了方便调试,分析网页爬取失败的具体原因,我们可以把需要的错误信息输出到 错误日志 里。
def saveErrorLog(url, err):
"""
url: 爬取失败的网页链接
err:错误信息
"""
with open("log.txt", "a") as f:
f.writeline(url)
f.writeline(err)
f.writeline("------"*10)
def spider(url):
try:
r = requests.get(url)
......
except Exception as e:
# 错误信息写入日志,方便后续调试
saveErrorLog(url, e)在爬取结束后,我们可以根据日志文件,对爬取失败的网页一一进行分析,确定爬取失败的具体原因,并根据这些信息来优化我们的爬虫。
9. 大文件的分批读取
当我们处理一个较大的文件时,一次性加载到内存可能会导致内存溢出,这时候就需要分批来读取。
9.1 pandas 分批读取大文件
在爬取新闻文章时,我经常收到一个需求,就是把正文内容跟别的信息一起存放到同一个 csv 文件中,这样的话,当爬取的新闻数量较大时,生成的 csv 文件体积也会变得特别的大。
在后续分析处理这个大文件时,如果使用 pandas 直接打开文件,就会出现内存溢出打开失败的报错。
pandas 提供了一种以迭代器的方式读取文件,将文件分批读取到内存里。
示例代码如下:
import pandas as pd
row_list = []
try:
reader = pd.read_csv(filename, encoding='utf-8', header=None, iterator=True, chunksize=1000)
for chunk in reader:
row_list.extend(chunk.values.tolist())
except:
pass
for row in row_list:
print(row)通过参数 chunksize 可以设置每个批次读取的数据条数,如以上代码中,每批读取 1000 条数据。
顺便插一句,我其实不太理解这样的需求。
可能有人觉得把所有数据放一个文件里,查看起来会比较方便。但是要知道,这么大数据量的情况下,你基本是不可能手动去查看的,都是用代码处理的。而用代码处理分析的话,数据放一个文件里和放多个文件里,是没什么区别的。
把所有数据放同一个文件里,优点基本可以忽略不计,但是缺点却有一大堆:
- 正文内容一般很长,存放在同一个 csv 中会导致单个文件体积过大,打开、查阅、处理起来都会很卡。
- 正文内容中,各种字符都有可能出现,如果出现如英文逗号
,等符号,会直接导致 csv 解析错误。- 数据保存时候,读写都是同一个文件,没法用多线程(用了也提升不大),影响效率。
- 一旦程序出错,写入了脏数据,很可能整个文件就废了,一切得从头重新开始。
- ......
相比之下,我更喜欢把
新闻标题,原文地址,新闻出处,发布日期等信息合并放在 csv 中,正文内容保存在单独的文件里(文件名记录在 csv 中)。需要查看正文时,通过 csv 表中记录的文件名即可找到对应的文件。当然,这是后话,大家可以根据自己的需求和习惯,选择适合自己的数据保存的形式。
9.2 requests 分段下载大文件
我们通过 requests 下载大文件时,一次性请求大量的数据,是比较有风险的——它需要等所有数据全部下载完毕后才能保存,数据量大时这个过程耗时会很长,不确定因素也有很多,很可能因为各种因素,如网络波动等,导致保存失败,前功尽弃。
与前面同理,requests 提供了流式下载的方法,可以将数据切分成多个 chunk,然后分批下载保存。
示例代码如下:
import requests
url = 'https://vd.xxxxxx.com/xxxx.mp4'
r = requests.get(url,stream=True)#stream=True设置流式下载
with open('aaa.mp4','wb') as file:
for i in r.iter_content(chunk_size=1024):
if i:
file.write(i)大家在下载大文件,如视频时,可以使用这种方式。
10. 参数可以放到配置文件里
为了提高程序的灵活性,我们可以把一些经常需要变动的参数放到配置文件里,这样每次修改参数时,不需要修改代码。
例如,在新闻爬虫的项目中,我将数百个搜索关键词放到了配置文件里。
示例代码如下:
# 关键词配置文件为 keywords.txt,每个关键词独占一行
def readKeywords(filename):
'''
读取配置文件,获取搜索关键词列表
'''
keywords = []
with open(filename, encoding="utf-8") as f:
keywords = f.readlines()
keywords = [kw.strip() for kw in keywords]
return keywords
if __name__ == "__main__":
# 读取关键词列表,并去重
keywords = set(readKeywords("keywords.txt"))
print(len(keywords))
for kw in keywords:
print(kw)这样,如果需要增删或修改关键词,只需要调整配置文件,然后运行代码即可,非常方便。
如果文章中有哪里没有讲明白,或者讲解有误的地方,欢迎在评论区批评指正,或者扫描下面的二维码,加我微信,大家一起学习交流,共同进步。


